AnimateDiff :更优质的动画生成体验
近年来,AIGC 宛如 AI 海洋中最不可或缺的波涛,逐渐凝成滔天的巨浪,突破壁垒、扑向海岸,并酝酿着下一波潮水高涨。以 Stable Diffusion 这股翻腾最为汹涌的波涛为代表的文生图模型飞速发展,使得更多非专业用户也能通过简单的文字提示生成高质量的图片内容。然而,文生图模型的训练成本往往十分高昂,为减轻微调模型的代价,相应的模型定制化方法如 DreamBooth, LoRA 应运而生,使得用户在开源权重的基础上,用少量数据和消费级显卡即可实现模型个性化和特定风格下的图像生成质量的提升。这极大推动了 HuggingFace, CivitAI 等开源模型社区的发展,众多艺术家和爱好者在其中贡献了许多高质量的微调模型。不觉间,平静的海洋洪水滔天,海滩上留下数不清的色彩斑斓的鹅卵石,便是爱好者们精心调制的 AI 画作。
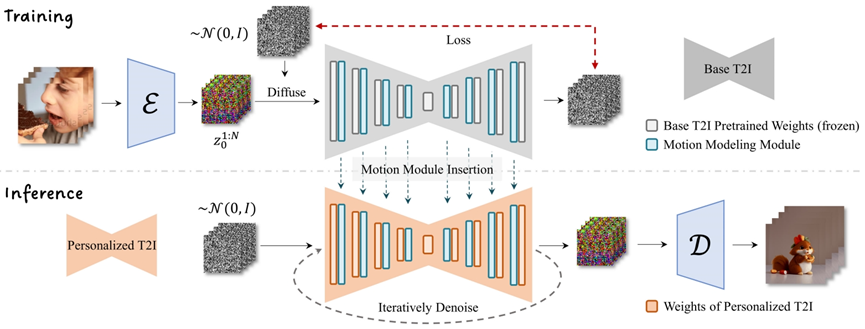
与动画相比,静态图像的表达能力是有限的。随着越来越多效果惊艳的微调模型的出现和视频生成技术的发展,人们期待着能够赋予这些定制化模型生成动画的能力。在最新开源的 AnimateDiff 中,作者提出了一种将任何定制化文生图模型拓展用于动画生成的框架,可以在保持原有定制化模型画面质量的基础上,生成相应的动画片段。为色彩斑斓的鹅卵石,增添一些动态的光泽。
项目地址:点我

为避免破坏原有文生图微调模型生成能力,AnimateDiff 在文生图模型中插入动作建模模块,并在视频数据上学习合理的动作先验。在训练过程中,首先对模型结构进行了扩展使之可以接受视频格式数据;同时在参数更新时保持原有文生图模型权重不变,使得训练后的网络权重可以即插即用地驱动不同版本的定制化微调模型,而无需针对相应模型做任何优化。在推理时,插入动作建模模块直接到相应定制化模型中,组合后的模型对采样的噪声序列去噪,生成相应的动画片段。
与现有方法相比,AnimateDiff 由于从大量视频中学习了合理的动作先验,生成的动画在连续性上表现更优。不同于现有大部分视频生成框架,由于锁定了文生图模型的权重,生成画面的质量相比原有模型并没有明显降低。