清华博士秦禹嘉最近发表一篇博文称:是时候把数据scale down了!
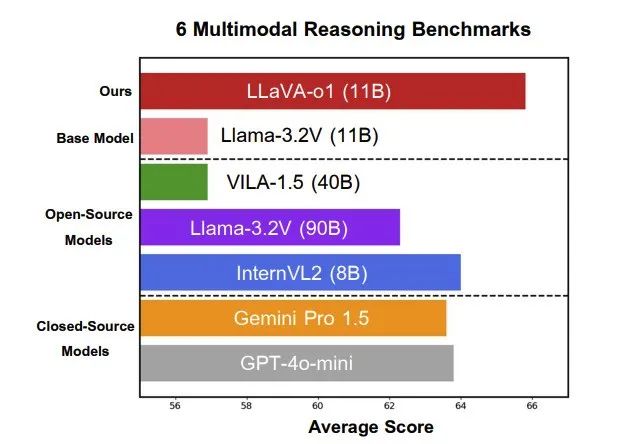
LLaMA3告诉大家一个悲观的现实:模型架构不用动,把数据量从2T加到15T就可以暴力出奇迹。
这一方面告诉大家基座模型长期来看就是大厂的机会;另一方面,考虑到scaling law的边际效应,我们想继续看到下一代模型能够有GPT3->GPT4的提升,很可能需要再洗出至少10个数量级的数据(e.g., 150T)。
近期DCLM的团队真从CommonCrawl里洗出来了240T数据,这给scaling law信奉者带来了福音:数据是不缺的,你有卡么?其实在数据这块,暴力scale up固然重要,如何scale down(同时把单位数据质量提升上去)也很重要。模型智能由数据的压缩而来;反过来,模型将会重新定义数据的组织形式。
总的来说,前scaling law时代强调的是scale up,即努力追求数据压缩后的模型智能上限,后scaling law时代大家比拼的是scale down,即谁能训练出“性价比”更高的模型。
目前主流的数据scale down手段就是基于模型的数据去噪。当前的方法仍然聚焦在单条数据的质量增强上,未来一个更重要的研究方向是如何做多条数据语义级别的去重/合并,这块很难,但是对数据scale down意义重大。
论文地址:https://arxiv.org/abs/2406.11794