
OpenAI 正式推出了GPTs Store 和ChatGPT Team订阅计划
已经有超过300万个GPTs被创建 同时OpenAI将启动一个GPTs构建者收益计划,美国构建者将根据用户与他们的GPTs互动情况获得报酬。 ChatGPT Team订阅计划每月每用户25美元(年度计…
已经有超过300万个GPTs被创建 同时OpenAI将启动一个GPTs构建者收益计划,美国构建者将根据用户与他们的GPTs互动情况获得报酬。 ChatGPT Team订阅计划每月每用户25美元(年度计…

Genie是一个文本到3D模型的转换工具,能够在不到10秒内根据文本描述创建任何想象中的3D对象。 生成的3D模型不仅包含形状,还包含了表面材料的细节,比如颜色、纹理或反光性,这使得模型更加逼真和详细…
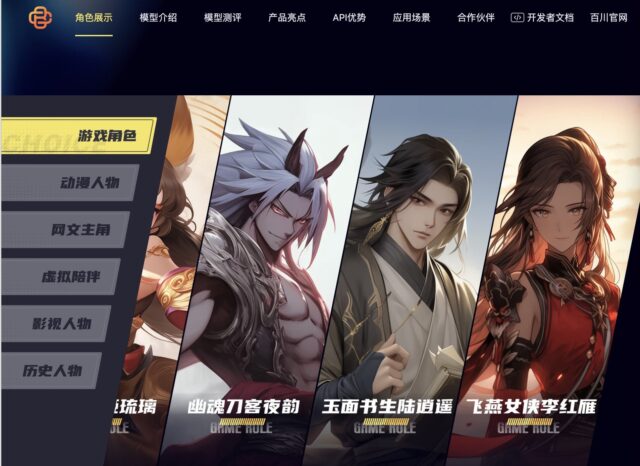
这些角色包括游戏角色、动漫人物、网文主角等。每个角色都有自己的背景故事和特点,为用户提供了丰富的互动体验。 百川称模型融合了角色知识库和多轮记忆能力,增强了对话和逻辑能力,使得角色扮演更为栩栩如生。 …

Midjourney 被曝光未经许可使用了包含 16000 名艺术家的作品风格来训练其图像生成AI。 这个名单不仅包括现代和当代著名艺术家的作品,还包括了为公司如Hasbro和Nintendo工作的商…

通过脑电波控制波士顿动力的机器狗。 该技术仅靠一种特殊的眼镜就能读取人的脑电波和眼动,然后把这些信号传递给机器人执行动作。 Ddog系统只需要两 iPhone和一副蓝牙眼镜就可以运行。而且还可以完全离…

该技术可以在照片中加入一个看起来像是真实反射环境的铬球。这个铬球可以帮助计算出照片中的光照是怎样的。 然后,他们使用这些光照信息在照片中添加新的物体,使得这些物体看起来好像是在原来的光照条件下拍摄的一…

你只需要通过文字描述人的脸型、五官、发型等特征,它就能在不到2分钟的时间内生成一个超逼真的3D角色。 而且你可以自定义面部特征,例如脸型、眼睛颜色、发型、眉毛类型、嘴巴和鼻子,以及添加皱纹和雀斑等。 …
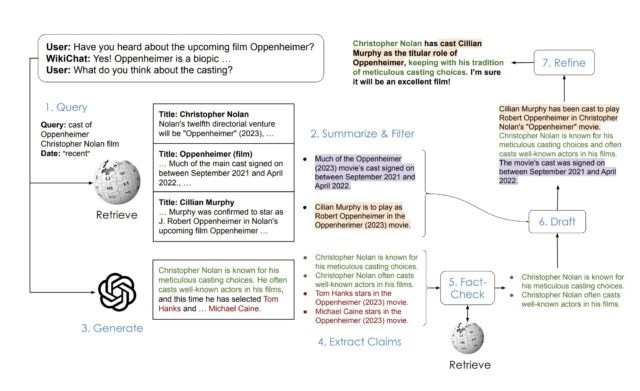
WikiChat基于英文维基百科信息。当它需要回答问题时,会先在维基百科上找到相关的、准确的信息,然后再给出回答,保证给出的回答既有用又可靠。 在混合人类和LLM的评估中,WikiChat达到了97….

– Rodin Gen-1拥有1.5B参数,是目前最大的3D原生生成大模型。它的功能类似于SD(Stable Diffusion)。 – 3D-to-3D:除了传统的3D建模,…
– 同时拨打或接听多大500000个电话 – 保证和人类接听员一样的水准,自然且流畅 – 可以创建声音克隆,模仿任何人的声音 – 对其进行编程以执行任何…
– 2023年,越来越多的开发者开始使用AI技术,同时也尝试构建基于AI的应用程序。 – 基于OpenAI等公司的基础模型的生成性AI项目数量激增,其中一些项目甚至进入了最受欢…
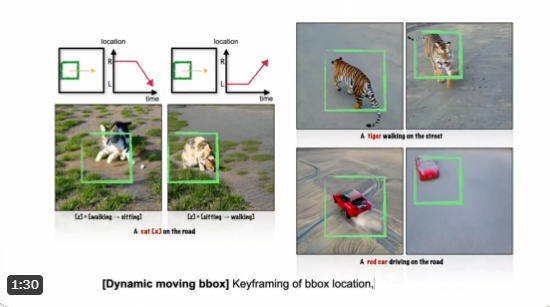
TrailBlazer是英伟达的一个预训练好的模型,只需输入文本即可生成视频。 同时他们提出一个边界框的概念,来控制视频对象的运动方向、速度和行为。 例如,你可以通过改变边界框的大小、方向,让视频中的…

Perplexity公布了一些数据: – Perplexity 的月活跃用户增长到了1000万 – 2023年,Perplexity处理了超过5亿次查询 – 超过1…
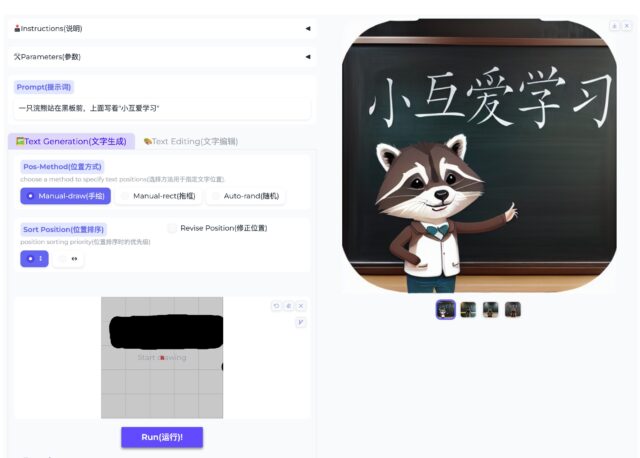
该项目由阿里巴巴开发,AnyText支持在图像中生成和编辑多种语言的文本,使其与背景无缝融合。 该模型还解决了合成文本中模糊、不可读或错误字符的问题。 AnyText可以与现有的扩散模型集成,用于准确…
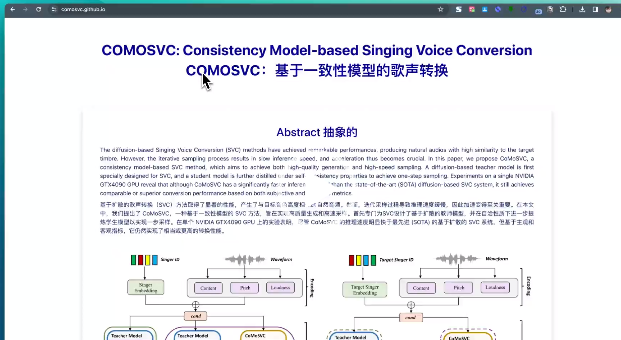
它可以将一个人的歌声转换成另一个人的歌声。同时能够保持了声音的自然度和真实感。 最牛P的是CoMoSVC实现了一步采样。意思是它可以在单次操作中即可完成声音的转换,大大加快了处理速度。 该项目由香港大…

它可以从多人对话中语音中生成与对话相对应的逼真面部表情、完整身体和手势动作。 这些生成的虚拟人物不仅在视觉上很逼真,而且能够准确地反映出对话中的手势和表情细节,如指点、手腕抖动、耸肩、微笑、嘲笑等。 …

The Information 报道,两名与OpenAI 谈判的媒体高管透露,OpenAI已经向一些媒体公司开出了每年 100 万-500 万美元,以获得将新闻内容用于训练自家大语言模型的授权许可。 …

由坦福大学开发,专门设计用于执行需要双手和全身协调的复杂移动任务。 可以通过模仿学习(即观察人类操作然后模仿这些动作),仅通过50次任务演示,共同训练,它就能够自主完成日常生活中的各种任务。 如做饭、…

能根据音频让人物头像照片说话、唱歌同时保持嘴型和表情一致。 GitHub:https://github.com/ali-vilab/dreamtalk HuggingFace:https://hugg…
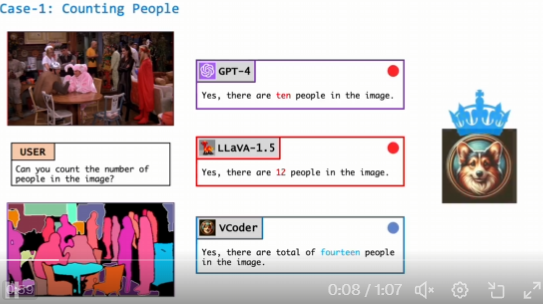
VCoder的一个视觉编码器,能够帮助MLLM更好地理解和分析图像内容。提高模型在识别图像中的对象、理解图像场景方面的能力。 它可以帮助模型显示图片中不同物体的轮廓或深度图(显示物体距离相机的远近)。…