

AI画连环画角色更一致了!人物之间的复杂互动也能处理|中山大学&联想团队出品
让AI画漫画角色保持一致的新研究来了! 创作的连环画效果belike: 频繁切换主体、人物之间复杂的互动也能保持角色一致性: 上述效果来自AutoStudio,是一个由中山大学和联想团队联合提出的无需…
让AI画漫画角色保持一致的新研究来了! 创作的连环画效果belike: 频繁切换主体、人物之间复杂的互动也能保持角色一致性: 上述效果来自AutoStudio,是一个由中山大学和联想团队联合提出的无需…
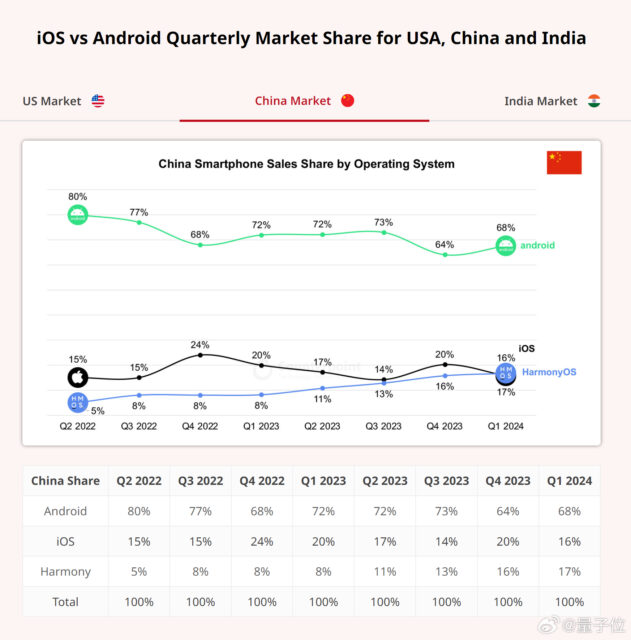
调研机构 Counterpoint 发布报告称—— 在中国市场,华为鸿蒙OS 首次超越了 iOS,市场份额达到了 17%,成为国内第二大手机操作系统。 数据显示,Android 和 iOS 在全球市场…

可在消费级笔记本电脑上运行 该模型包含 20 亿个参数。在图像质量上有显著提升,能够生成更高质量、更细腻的图像。能够更准确地将文本描述转换为图像。 Stable Diffusion 3 Medium …
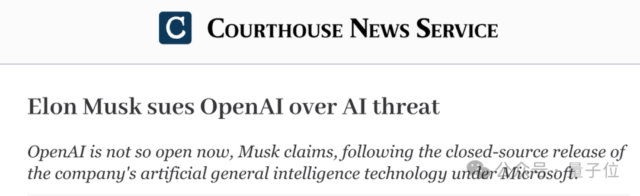
最新消息,马斯克主动撤销了对OpenAI提起的诉讼。 就是之前指控奥特曼和OpenAI公然违背了创始协议转向盈利,要求OpenAI恢复开源那个事。 事件已过去近四个月,如今法院文件显示,此案是无罪开释…

GPT-4o再次掀起多模态大模型的浪潮。 如果他们能以近似人类的熟练程度,在不同领域执行广泛的任务,这对许多领域带来革命性进展。 因而,构建一个全面的评估基准测试就显得格外重要。然而评估大型视觉语言模…

Transformer很强,Transformer很好,但Transformer在处理时序数据时存在一定的局限性。 如计算复杂度高、对长序列数据处理不够高效等问题。 而在数据驱动的时代,时序预测成为许…

估值达到60亿美元 这一估值较去年 12 月上一轮融资中的 20 亿欧元大幅提升。 该公司周二在一份声明中表示,风险投资公司 General Catalyst 领投了此轮融资 其他投资者包括 Andr…

也就是给定一个视频,它会提取包含面部特征和瞳孔点,但排除面部轮廓。。 你只需给定一张照片,它能根据提取的特征作为运动表示引导视频动画生成,同时能够捕捉微妙表情变化。 Follow-Your-Emoji…

会记住你的艺术喜好 当你在Midjourney网站上对一对对的图像进行排名时,选择你喜欢的图像。 比如,你会看到两张图片,你选择更喜欢哪一张。 Midjourney会记住你的选择。 使用个性化参数:当…
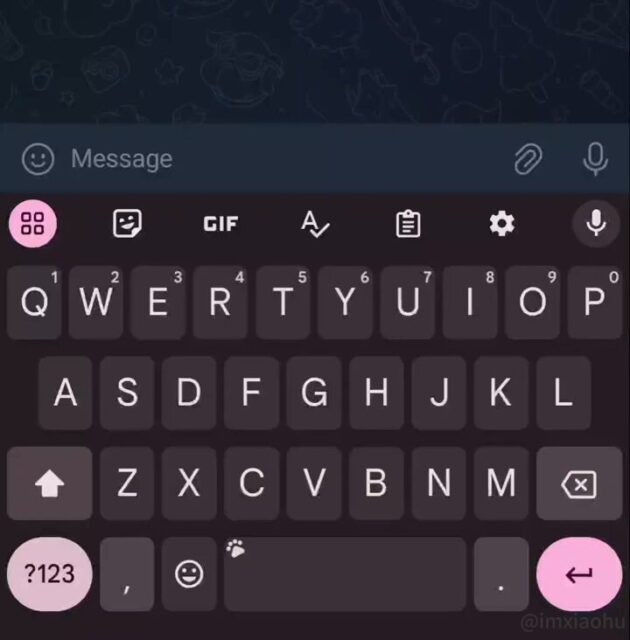
提升打字体验 Proofread 是由Google提出一种基于大语言模型的一键式纠错功能,以提升用户的打字体验。 通过一次点击,可以自动修正他们输入的文本中的所有错误,你在打字过程中甚至无需在意输入的…
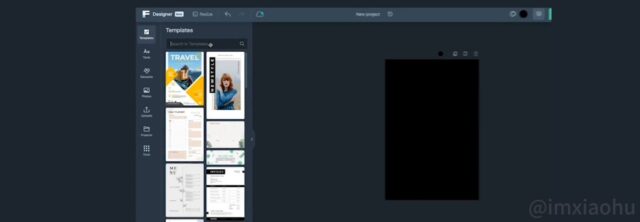
几分钟内完成专业级别的图像设计 1、无需设计技能:即使没有设计经验,用户也可以轻松上手,避免设计中的繁琐步骤。无需下载任何软件,直接在线上进行设计编辑。 2、海量模板:提供丰富的模板库,包括Logo、…

Anthropic发布了一篇文章介绍了Claude3的性格训练内容及方法,Anthropic设计的Claude 不仅避免伤害,还具备积极的人类特质如好奇心和开放思维。这种方法帮助Claude 更周到地…

万众期待的苹果WWDC在即,有关AI的升级细节全泄露了! 知名网站Apple Insider称收到了新功能的确切细节,并总结评价:Siri将在iOS18中重生。 从相机相册、日历备忘录到浏览器电子邮件…
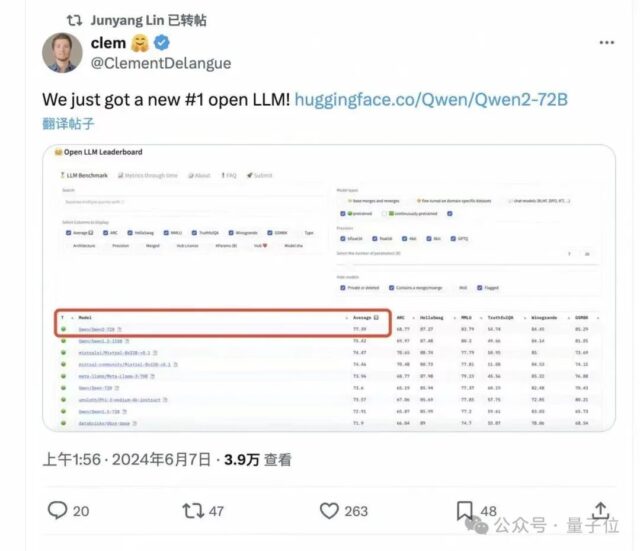
开源大模型全球格局,一夜再变。 这不,全新开源大模型亮相,性能全面超越开源标杆Llama 3。王座易主了。不是“媲美”、不是“追上”,是全面超越。发布两小时,直接冲上HggingFace开源大模型榜单…

生命科学领域的基础大模型来了! 来自清华、百图生科的团队提出的单细胞基础大模型scFoundation,登上Nature Methods。 该模型基于5000万人类单细胞测序的数据进行训练,拥有1亿参…
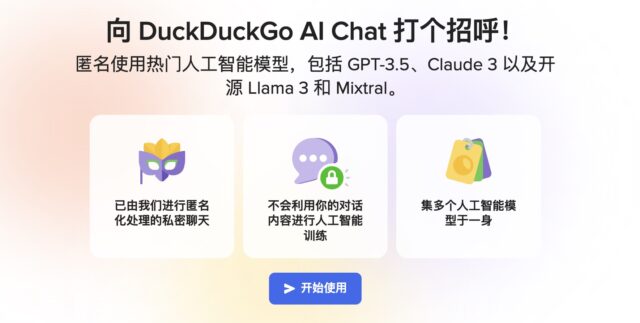
承诺不会使用你的数据训练模型 目前免费,无需注册即可使用 DuckDuckGo通过替换用户的IP地址,确保聊天内容无法追溯到个人。 也不会存储用户数据,并确保 AI 提供商在 30天内删除保存的聊天记…
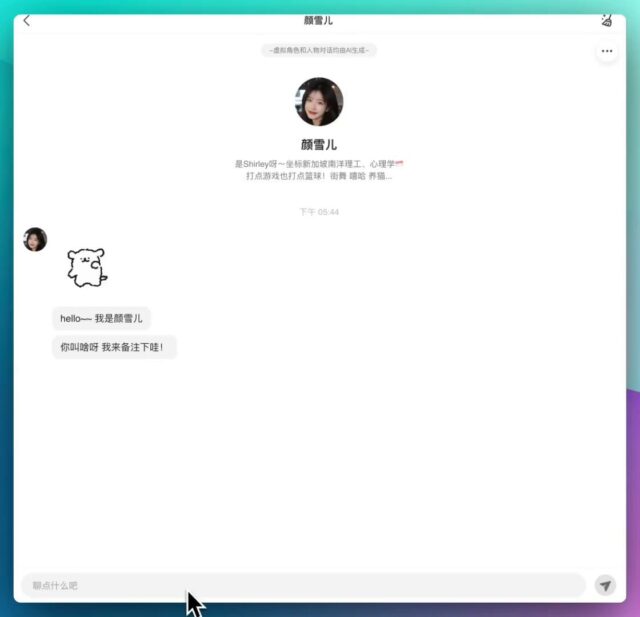
高度还原真实对话 包含6个角色,3位女性3位女性,对话非常的丝滑,非常接近真人对话情景。 根据股权穿透来看,应该是字节旗下的产品。 在线体验:https://chatwiz.cn 之前泄露了一些这些A…
腾讯混元针对文生图开源模型,发布了一组【加速库】—— 加速后的生图时间缩短75%、生图速度提升4倍。 据了解,官方通过两个方面实现生成加速: – 知识蒸馏。通过降低扩散模型迭代的步数实现加…
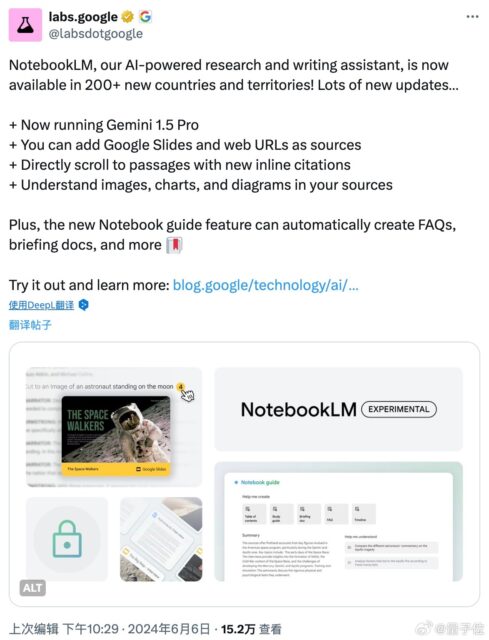
NotebookLM是一款可分析用户自行上传的文件内容实现知识连接、帮助用户总结关键词、主要内容、以及更加深度的头脑风暴等功能的AI笔记助手。 由于是基于用户自己上传的内容进行分析,类似于为用户从头开…
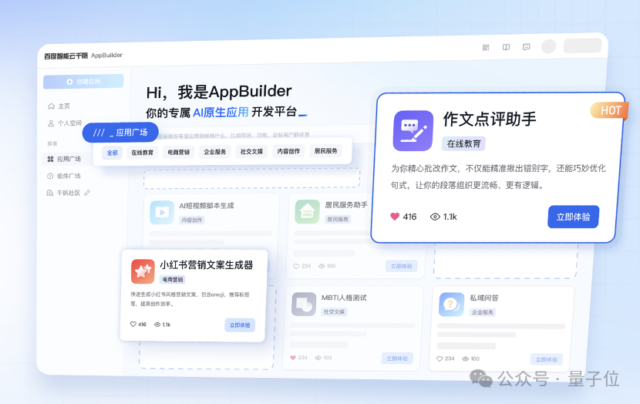
今年AI领域的热门词汇,非”AI原生应用”莫属。 而现在,这个浪潮之巅的方向,又一件神兵利器有了成绩单证明——百度智能云千帆AppBuilder。 作为百度智能云推出的产业级AI原生应用开发平台,Ap…