

AI虚拟角色国内产品榜TOP15
AI智能助手,代表的是生产力方向。 AI陪伴,则是从互动娱乐的方向,展开最in AI原生产品的竞逐。 现在,无论是角色扮演、虚拟恋人还是日常陪伴,AI陪伴产品正在用AIGC技术,以产品化形态,来到了台…
AI智能助手,代表的是生产力方向。 AI陪伴,则是从互动娱乐的方向,展开最in AI原生产品的竞逐。 现在,无论是角色扮演、虚拟恋人还是日常陪伴,AI陪伴产品正在用AIGC技术,以产品化形态,来到了台…

• 能够通过简单的文本提示生成最长47秒的立体声音频(44.1kHz)。 • 适用于创建鼓点、乐器片段、环境声音和拟音录音等。 • 基于transforms扩散模型(DiT),在自动编码器的潜在空间中…

该模型能够生成高质量、几乎无法与人类声音无法区分的语音。 无需训练的情况下,只需要简短的语音片段即可克隆生成高度自然且富有表现力的语音。 完全能否胜任读小说、配音等任务 Seed-TTS 还提供了对各…

Mobile-Agent 是一个通过多种技术手段,实现了对移动设备的自动化操作和视觉感知功能。 也就是让AI可以像你一样模拟点击、滑动、输入等操作,来操控你的手机,来帮你自动完成一些列任务。 例如: …
让小爱音箱和其他米家智能设备能更好地理解和响应用户指令,并且还可以直接和智能家居联动! 主要功能: 1. 小爱音箱可以使用 ChatGPT 等大模型来回答问题。 2.角色扮演:小爱音箱可快速切换角色,…

更快的速度,更低的价格 性能提升40% 超越Llama 3 GLM 4V 9B能力比肩GPT 4V 支持1M无损上下文,26种语言,函数调用能力提升40%,比肩GPT 4V

该助手能通过语音为玩家提供实时的游戏评论和建议,包括购买建议、对线策略等。 玩家可以在比赛中提出任何关于游戏的问题,并立即获得解答。 每场比赛结束后,玩家可以在赛后大厅页面查看比赛总结,包括各个玩家的…

在2021年夏天,OpenAI宣布关闭其机器人团队,原因是缺乏必要的数据来训练机器人如何使用人工智能进行移动和推理。 然而,OpenAI的三位早期研究科学家表示,他们在2017年从OpenAI剥离成立…
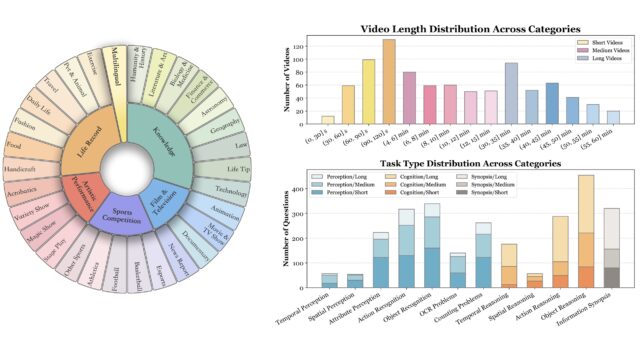
该基准由来自多个大学和研究机构的研究人员共同开发,旨在通过多样化和高质量的数据集,全面考察MLLMs在处理视频数据时的能力。 视频数据集涵盖6个主要视觉领域,包括知识、电影与电视、体育竞技、艺术表演、…
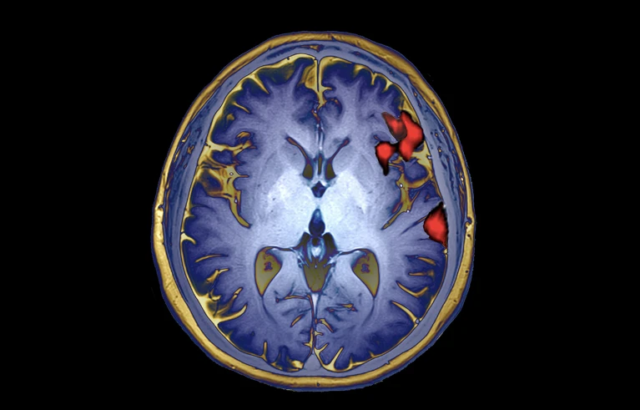
加州大学旧金山分校的研究人员刚刚开发出一种大脑植入物,研究人员成功地帮助一名失去说话能力的双语患者通过脑植入设备实现了双语交流。 这一系统由人工智能(AI)与脑植入设备结合而成,能够实时解码患者试图表…

新规则允许用户在 X 平台上发布经过双方同意制作的成人内容。 此更改也适用于AI生成的视频和图像。 为了确保这些内容不会无意间暴露给不愿意看到它们的用户,X要求发布者显著标记这些内容。 平台强调,性表…

消息称苹果将对Siri进行基于人工智能的重大改造 通过这种改进,你将能够通过Siri语音操控手机内的各个应用功能,从而提升整体使用体验。

根据新版隐私权政策,用户将同意将自己发布的任何内容用于 AI at Meta 模型训练。 如果用户选择不同意该隐私权政策则应该主动停止使用 Facebook 和Instagram等产品,否则均为接受新…
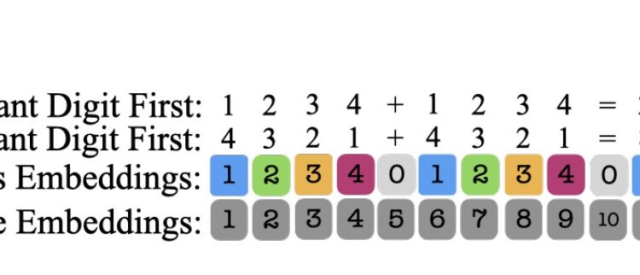
传统的transformer在处理长数字序列时,难以准确地跟踪和表示每个数字的位置,导致在进行多步骤和拿杂运算时性能不理想。 通过引入一种新的位置嵌入方法(Abacus Embeddings),研究人…

可以让游戏NPC具有AI对话功能,同时能直接生成数字人的语音和面部动画! Avatar Cloud Engine (ACE)是一项用于提升游戏和虚拟角色互动体验的技术。 1.赋予游戏角色智能:ACE可…

可以在几十秒内通过文本生成高质量可直接使用的3D模型,这些模型使用四边形构造,并具有逼真的材质效果(看起来很真实)。 Rodin几乎达到了可以在实际项目和商业用途中直接应用的标准。 生成的3D模型质量…
据 Forbes 爆料,OpenAI 正在重组于2020年解散的机器人团队。 该公司正在招聘研究工程师,以组建一个新的团队,目前已经存在约两个月。 OpenAI 尚未公开详细介绍其机器人计划,但在最近…
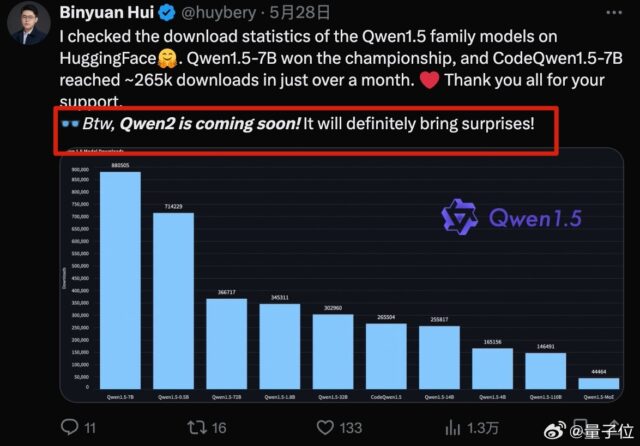
Qwen1.5 来了,Qwen2还会远吗 还在上个月,阿里推出了国内开源模型中参数规模最大的 Qwen1.5-110B 模型。 根据官方公布的评测结果,Qwen1.5-110B略超过Llama-3-7…

清华类脑计算研究中心施路平团队新成果,登上最新一期Nature封面。 团队研发出世界首款类脑互补视觉芯片——“天眸芯”。 “天眸芯”实现了一种基于视觉原语的互补双通路类脑视觉感知新范式,模仿了人类视觉…

由Cartesia AI开发,基于他们自研的状态空间模型 • 延迟仅为135毫秒,确保实时响应 • 超逼真语音:生成富有情感和表达力的真人语音 • 只需10秒的录音即可匹配语调、抑扬顿挫和声线特征。 …