
开源超闭源!通义千问Qwen2发布即爆火,网友:GPT-4o危
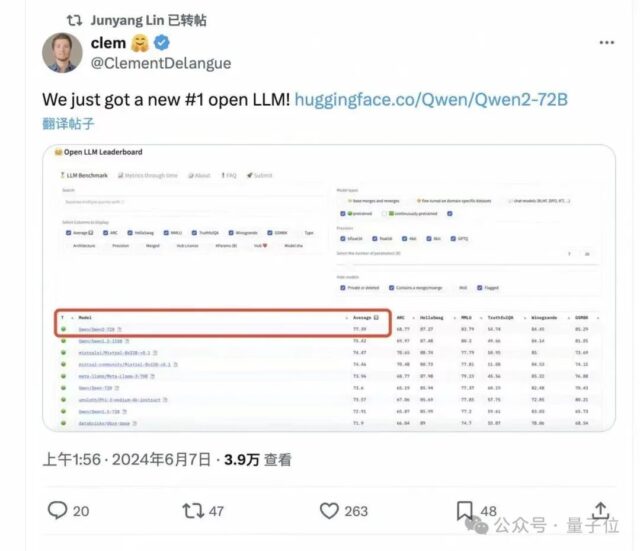
开源大模型全球格局,一夜再变。 这不,全新开源大模型亮相,性能全面超越开源标杆Llama 3。王座易主了。不是“媲美”、不是“追上”,是全面超越。发布两小时,直接冲上HggingFace开源大模型榜单…
开源大模型全球格局,一夜再变。 这不,全新开源大模型亮相,性能全面超越开源标杆Llama 3。王座易主了。不是“媲美”、不是“追上”,是全面超越。发布两小时,直接冲上HggingFace开源大模型榜单…

生命科学领域的基础大模型来了! 来自清华、百图生科的团队提出的单细胞基础大模型scFoundation,登上Nature Methods。 该模型基于5000万人类单细胞测序的数据进行训练,拥有1亿参…
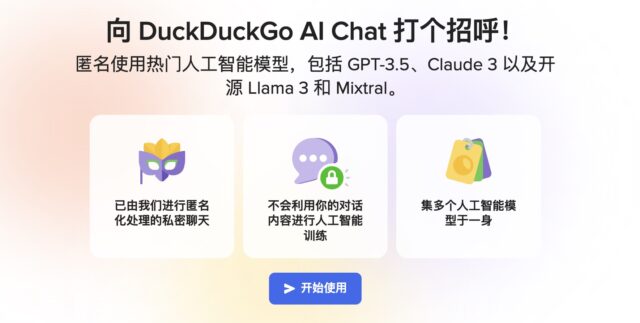
承诺不会使用你的数据训练模型 目前免费,无需注册即可使用 DuckDuckGo通过替换用户的IP地址,确保聊天内容无法追溯到个人。 也不会存储用户数据,并确保 AI 提供商在 30天内删除保存的聊天记…
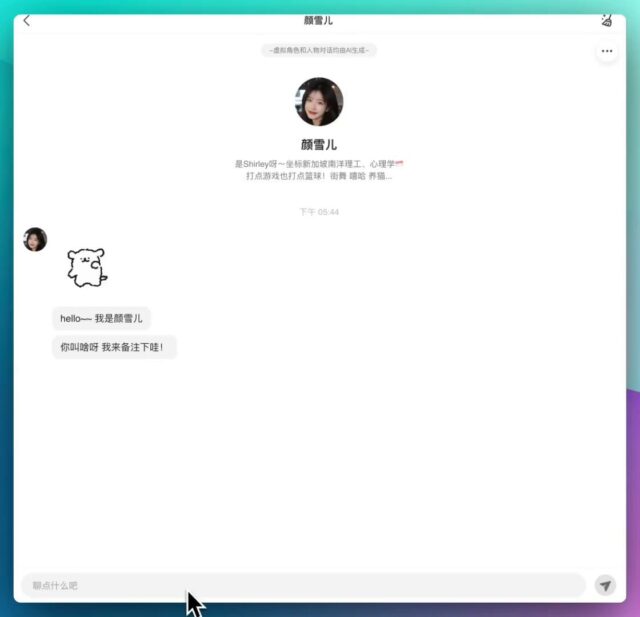
高度还原真实对话 包含6个角色,3位女性3位女性,对话非常的丝滑,非常接近真人对话情景。 根据股权穿透来看,应该是字节旗下的产品。 在线体验:https://chatwiz.cn 之前泄露了一些这些A…
腾讯混元针对文生图开源模型,发布了一组【加速库】—— 加速后的生图时间缩短75%、生图速度提升4倍。 据了解,官方通过两个方面实现生成加速: – 知识蒸馏。通过降低扩散模型迭代的步数实现加…
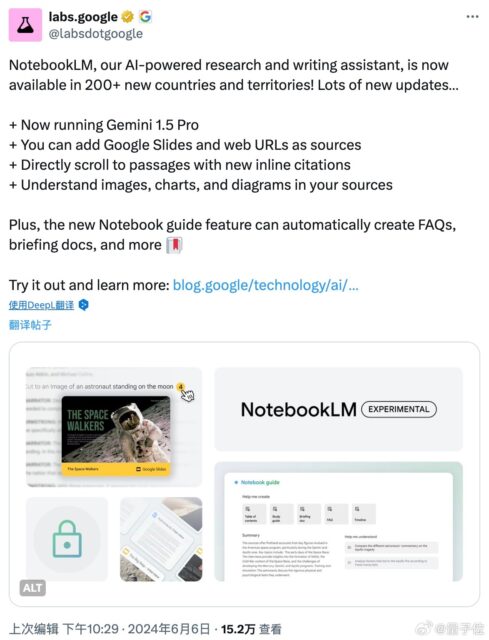
NotebookLM是一款可分析用户自行上传的文件内容实现知识连接、帮助用户总结关键词、主要内容、以及更加深度的头脑风暴等功能的AI笔记助手。 由于是基于用户自己上传的内容进行分析,类似于为用户从头开…
今年AI领域的热门词汇,非”AI原生应用”莫属。 而现在,这个浪潮之巅的方向,又一件神兵利器有了成绩单证明——百度智能云千帆AppBuilder。 作为百度智能云推出的产业级AI原生应用开发平台,Ap…

AI智能助手,代表的是生产力方向。 AI陪伴,则是从互动娱乐的方向,展开最in AI原生产品的竞逐。 现在,无论是角色扮演、虚拟恋人还是日常陪伴,AI陪伴产品正在用AIGC技术,以产品化形态,来到了台…

• 能够通过简单的文本提示生成最长47秒的立体声音频(44.1kHz)。 • 适用于创建鼓点、乐器片段、环境声音和拟音录音等。 • 基于transforms扩散模型(DiT),在自动编码器的潜在空间中…

该模型能够生成高质量、几乎无法与人类声音无法区分的语音。 无需训练的情况下,只需要简短的语音片段即可克隆生成高度自然且富有表现力的语音。 完全能否胜任读小说、配音等任务 Seed-TTS 还提供了对各…

Mobile-Agent 是一个通过多种技术手段,实现了对移动设备的自动化操作和视觉感知功能。 也就是让AI可以像你一样模拟点击、滑动、输入等操作,来操控你的手机,来帮你自动完成一些列任务。 例如: …
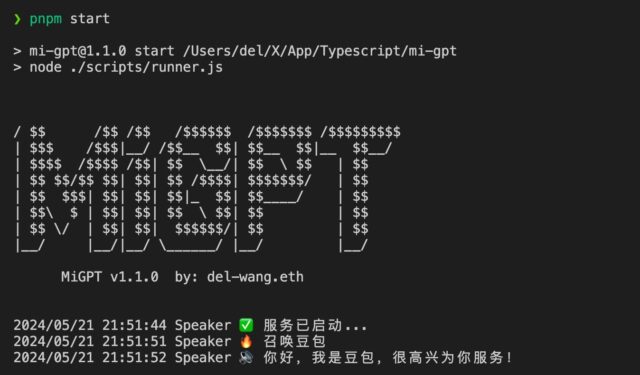
让小爱音箱和其他米家智能设备能更好地理解和响应用户指令,并且还可以直接和智能家居联动! 主要功能: 1. 小爱音箱可以使用 ChatGPT 等大模型来回答问题。 2.角色扮演:小爱音箱可快速切换角色,…

更快的速度,更低的价格 性能提升40% 超越Llama 3 GLM 4V 9B能力比肩GPT 4V 支持1M无损上下文,26种语言,函数调用能力提升40%,比肩GPT 4V

该助手能通过语音为玩家提供实时的游戏评论和建议,包括购买建议、对线策略等。 玩家可以在比赛中提出任何关于游戏的问题,并立即获得解答。 每场比赛结束后,玩家可以在赛后大厅页面查看比赛总结,包括各个玩家的…

在2021年夏天,OpenAI宣布关闭其机器人团队,原因是缺乏必要的数据来训练机器人如何使用人工智能进行移动和推理。 然而,OpenAI的三位早期研究科学家表示,他们在2017年从OpenAI剥离成立…
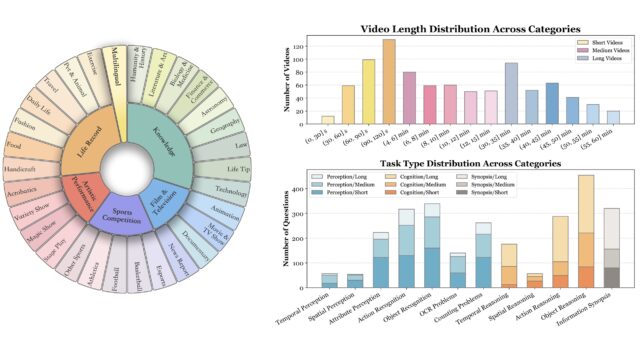
该基准由来自多个大学和研究机构的研究人员共同开发,旨在通过多样化和高质量的数据集,全面考察MLLMs在处理视频数据时的能力。 视频数据集涵盖6个主要视觉领域,包括知识、电影与电视、体育竞技、艺术表演、…
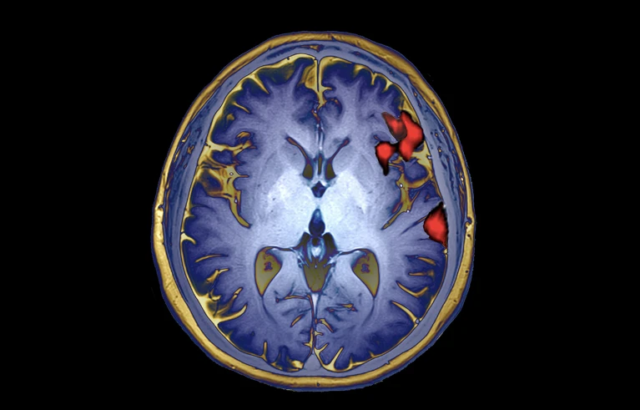
加州大学旧金山分校的研究人员刚刚开发出一种大脑植入物,研究人员成功地帮助一名失去说话能力的双语患者通过脑植入设备实现了双语交流。 这一系统由人工智能(AI)与脑植入设备结合而成,能够实时解码患者试图表…

新规则允许用户在 X 平台上发布经过双方同意制作的成人内容。 此更改也适用于AI生成的视频和图像。 为了确保这些内容不会无意间暴露给不愿意看到它们的用户,X要求发布者显著标记这些内容。 平台强调,性表…

消息称苹果将对Siri进行基于人工智能的重大改造 通过这种改进,你将能够通过Siri语音操控手机内的各个应用功能,从而提升整体使用体验。

根据新版隐私权政策,用户将同意将自己发布的任何内容用于 AI at Meta 模型训练。 如果用户选择不同意该隐私权政策则应该主动停止使用 Facebook 和Instagram等产品,否则均为接受新…