
Mistral发布7B模型0.3版本
抱抱脸上线了 Mistral-7B-v0.3 的基础版和指令微调版。 相比于Mistral-7B-v0.2,新版本更新如下: – 词汇量从 32000 扩展到 32768 – …
抱抱脸上线了 Mistral-7B-v0.3 的基础版和指令微调版。 相比于Mistral-7B-v0.2,新版本更新如下: – 词汇量从 32000 扩展到 32768 – …

王小川在搜索时期种下的种子,在大模型时代又开花了。 他创业的百川智能,刚刚发布了自家首款AI应用,to C的“百小应”。 乍一看,这就是个当下大热门的AI助手,但官方强调,这个AI助手啊,它懂搜索,还…

“欧洲AI春晚”主论坛现场,李彦宏最新亮相,作为大会唯一受邀中国企业家,再一次为中国AI“代言”。 这场正在法国巴黎举办的大会全称“欧洲科技创新展览会”(Viva Technology),是欧洲规模最…
让大神Andrej Karpathy一键三连❤️(点赞+转发+评论),一个教你从头开始实现Llama3的代码库爆火。 X上转赞收藏量超6.8k,GitHub揽星2k+。 火就火在,它教你从头用Meta…

今天,微软的生产力革命有了最新进展—— 它正在将AI塞进所有可能找到的角落和缝隙。 除了在大会前一天就已剧透Copilot+PC,Build大会上微软还有超多释出成果: Copilot持续升级:自定义…
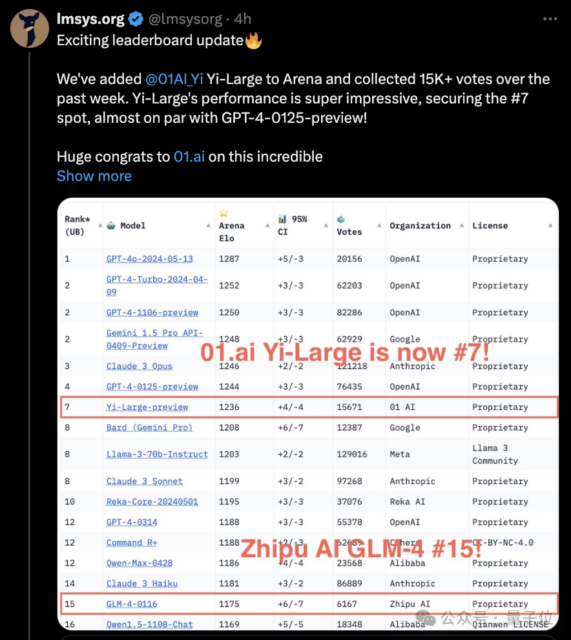
龙争虎斗的大模型竞技场,今天突然更新: 国内大模型公司零一万物旗下的Yi-Large千亿参数闭源大模型,跃升总榜第七,也成为榜上国产大模型第一。 可以看到,它的成绩几乎与GPT-4-0125-prev…
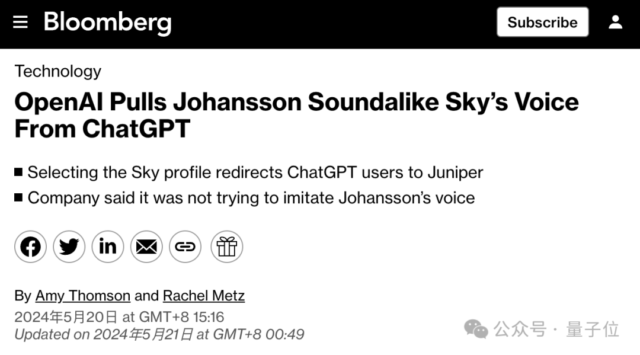
OpenAI的新王炸GPT-4o还没全面铺开,就摊上事了! 抓马的是,此次推出的“视频通话”功能一度被称为电影《Her》现实版,而怒斥OpenAI的刚好是给电影中AI配音的斯嘉丽·约翰逊(寡姐)。 寡…

通义千问GPT-4级大模型,直接击穿全网底价! 就在刚刚,阿里突然放出大招,官宣9款通义大模型降价。 其中,性能对标GPT-4的主力模型Qwen-Long,API输入价格从0.02元/千tokens降…
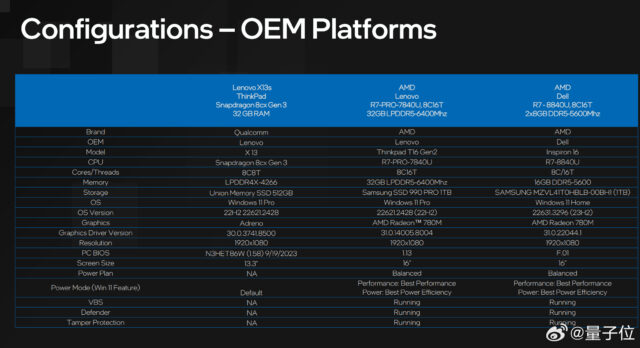
英特尔官方最新宣布—— 自今年第3季度起到假日季,其即将到来的客户端处理器 Lunar Lake 将继续扩大全球AI PC规模,并在未来可用时免费升级 Windows 11 AI PC体验。 Luna…
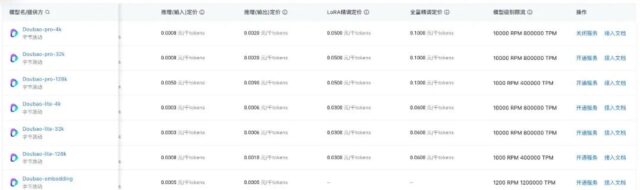
近期,火山引擎官网更新了豆包大模型的定价详情,全面展示豆包通用模型不同版本、不同规格的价格信息。 在模型推理定价大幅低于行业价格的基础上,豆包通用模型的 TPM(每分钟Tokens)、RPM(每分钟请…
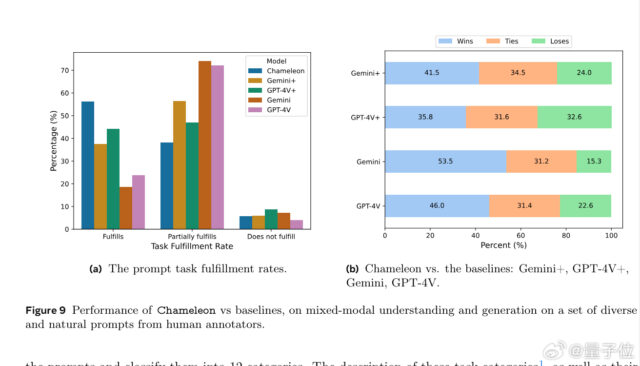
Meta 的 FAIR 团队新发表了一项名为 Chameleon 的研究。 该研究开发了一系列早期融合的混合模态基础模型,能够以任意顺序理解和生成图像和文本。 该模型在综合任务上进行了评估,包括视觉问…

丨划重点 ① 没有必要害怕超级智能的人工智能,因为与未来的模型相比,每个新模型都被认为能力不足,进而推动了持续的改进。 ② 仅仅专注于解决当前的人工智能限制可能是徒劳的,因为像GPT-5和GPT-6这…

通过手持式夹持器和精心设计的接口进行数据收集。 UMI可以将人类在复杂环境下的操作技能直接转移给机器人,无需人类编写详细的编程指令。 也就是通过人类亲自操作演示然后收集数据,直接转移到机器人身上,使得…

一款免费开源的 AI 浏览器,可以自动轻松地安装、运行和自动化任何 AI 应用程序和模型。支持运行如 SD、Fooocus、ComfyUI、SDXL Turbo、LCM、Whisper 等众多模型。并…
部分需要魔法,请自备,仅做整理,后期将出详细教程 LeiaPix: https://convert.leiapix.com/ CapCut: https://www.capcut.com (3D zo…

1、GFPGAN-腾讯开源的照片修复工具 https://github.com/TencentARC/GFPGAN 2、视频,图像和GIF无损放大/放大(超分辨率)和视频帧插值 https://git…

实际上大部分水印都是不可能去除的,这里说的不是各大平台的解析无水印下载,而是自带水印,只能遮盖水印,或者是模糊水印,又或者裁剪 1、Photoshop:必备技能,点击下载:Photoshop 2023…

OpenAI宣布ChatGPT的一项重要更新:增加了记忆功能和新的用户控制选项。 GPT现在可以在与用户的交互中跨聊天记住你们互动的所有信息,并在后续对话中利用这些信息来提供更相关和个性化的回答。 之…
CodeLlama-70B-Instruct 在 HumanEval 上获得 67.8 分,使其成为当今性能最高的开放模型之一。 Code Llama 70B分为三个版本: ◦ CodeLlama &…
