

Chatbot UI:一个开源的聊天机器人Web UI框架
支持接入OpenAI、Azure OpenAI、Anthropic、Google、Mistral和Perplexity等模型 同时支持Ollama上的本地模型接入。 这样你只需要输入这些模型的API,…
支持接入OpenAI、Azure OpenAI、Anthropic、Google、Mistral和Perplexity等模型 同时支持Ollama上的本地模型接入。 这样你只需要输入这些模型的API,…
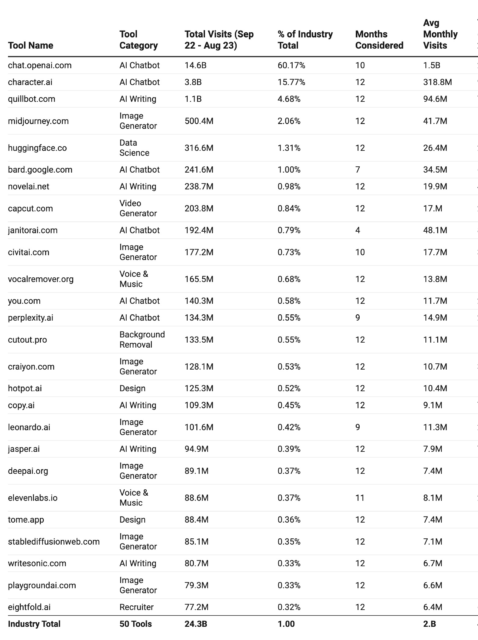
2023年50个访问量最大的AI工具及AI行业分析报告 Writerbuddy AI使用 SEO 行业著名的工具SEMrush,通过抓取AI工具数据,研究了3000多种 AI 工具。 从中选出了访问量…

能根据音频让人物头像照片说话、唱歌同时保持嘴型和表情一致。 GitHub:https://github.com/ali-vilab/dreamtalk HuggingFace:https://hugg…
– 2023年,越来越多的开发者开始使用AI技术,同时也尝试构建基于AI的应用程序。 – 基于OpenAI等公司的基础模型的生成性AI项目数量激增,其中一些项目甚至进入了最受欢…
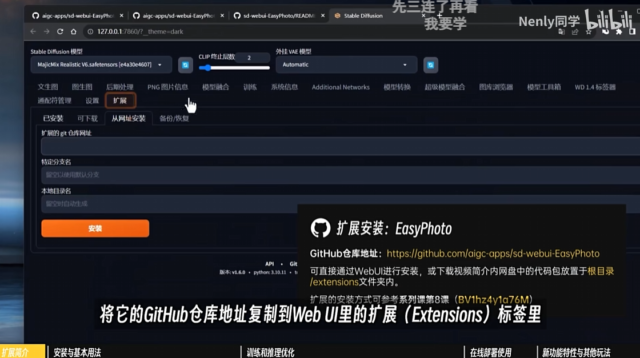
EasyPhoto扩展地址:https://github.com/aigc-apps/sd-webui-EasyPhoto 提示词模版和插件模型下载:https://nenly.notion.site…

RPG利用大语言模型来更好地理解和分解生成图像的文字提示,把一幅图像分解成不同的部分或区域。 然后对每个部分都根据理解的相应文本提示来生成图像,最后合成为一个符合你预期要求的图像。 该框架无需额外的模…

这个语音专文本TTS模型 应该是目前对中文支持最好的了 该模型经过超过10万小时的训练,公开版本在 HuggingFace 上提供了一个4万小时预训练的模型。 专为对话任务优化,能够支持多种说话人语音…
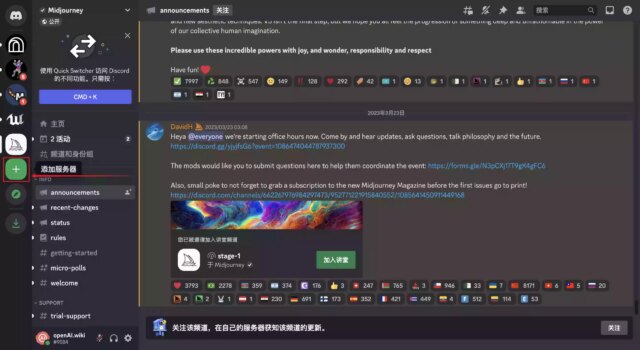
Midjourney进阶教程|私人服务器的使用与创建 自建服务器 首先我们点击Discord中最左侧的绿色添加服务器按钮,如下图所示: 在弹出的创建服务器界面内,点击亲自创建按钮。 左图中选择仅供我和…
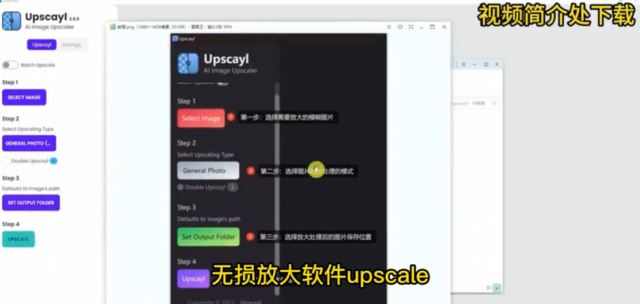
【下载地址】:https://pan.quark.cn/s/9f0fec66c8b7 国外爆火出圈!极品AI图片无损放大器,模糊图片秒变清晰,一键修图
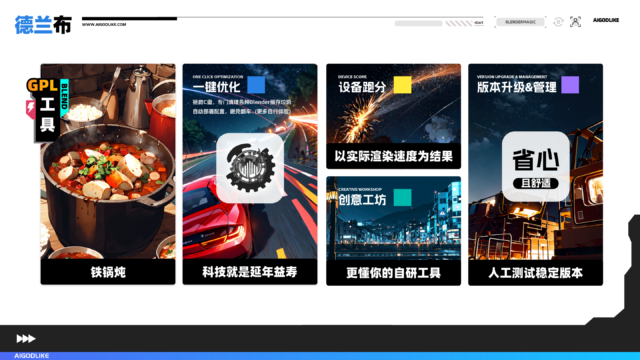
专为COMFYUI使用者设计,无论是在原生WEB还是Blender中使用,均可实现稳定且高效的对COMFYUI维护升级、一键优化和参数配置等功能。遵循免费和非广告使用原则,你可以在制作视频、讲演、授课…
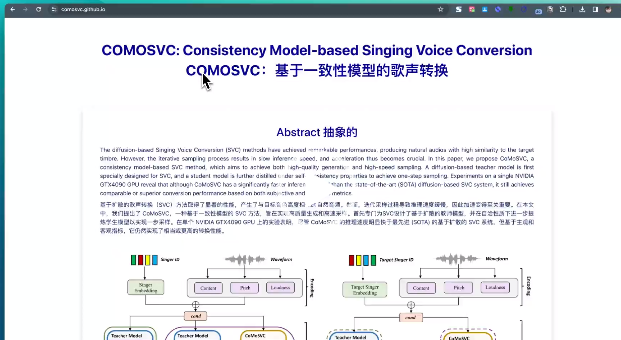
它可以将一个人的歌声转换成另一个人的歌声。同时能够保持了声音的自然度和真实感。 最牛P的是CoMoSVC实现了一步采样。意思是它可以在单次操作中即可完成声音的转换,大大加快了处理速度。 该项目由香港大…
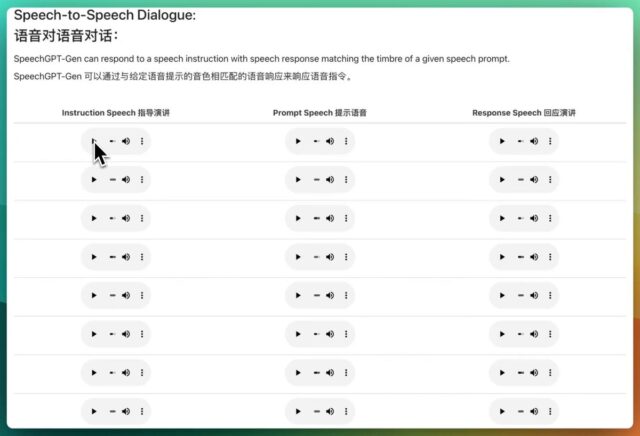
它不仅能处理传统的文本数据,还能理解和生成语音数据,实现文本与语音之间的无缝对话。 能够接收语音输入,理解其内容,并以语音形式做出回应。 为大语言模型在处理和生成语音方面提供了强大的支持。 Speec…

由坦福大学开发,专门设计用于执行需要双手和全身协调的复杂移动任务。 可以通过模仿学习(即观察人类操作然后模仿这些动作),仅通过50次任务演示,共同训练,它就能够自主完成日常生活中的各种任务。 如做饭、…
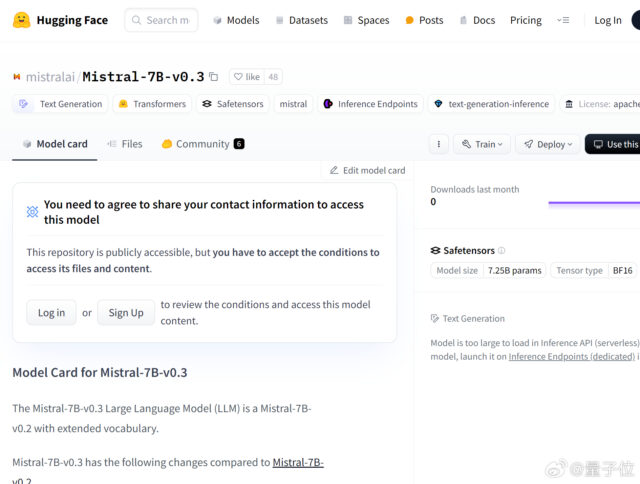
抱抱脸上线了 Mistral-7B-v0.3 的基础版和指令微调版。 相比于Mistral-7B-v0.2,新版本更新如下: – 词汇量从 32000 扩展到 32768 – …
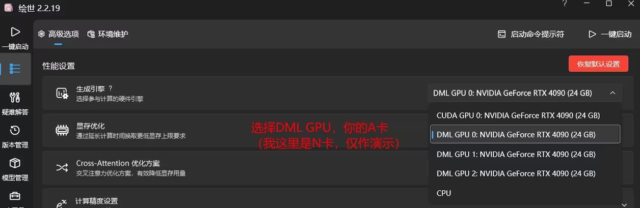
基于 lshqqytiger 分支制作,功能与 v4.4 版本整合包相同 仅经过朋友一台电脑测试,不保证完全可用,若发现无法使用请及时评论区反馈 使用方法和普通整合包完全一致,首次使用打开启启动器后,…

该模型能够生成高质量、几乎无法与人类声音无法区分的语音。 无需训练的情况下,只需要简短的语音片段即可克隆生成高度自然且富有表现力的语音。 完全能否胜任读小说、配音等任务 Seed-TTS 还提供了对各…
Stable Diffuxion出了新的更快的模型,SDXL Turbo 他到底有多快?废话不多说,先看网页版。 一个猫,在吃Cheese,绿色的盘子,戴一顶帽子,我都来不及解说了 你打字有多快,图就…
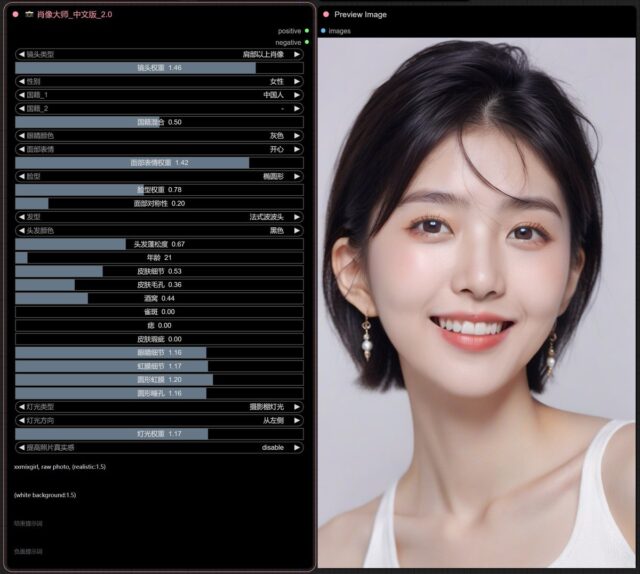
超详细参数设置!再也不用为不会写人像提示词发愁啦!重新优化为json列表更方便自定义和扩展!已包含标准工作流和turbo工作流. 肖像大师中文版2.0 :https://github.com/ZHO-…
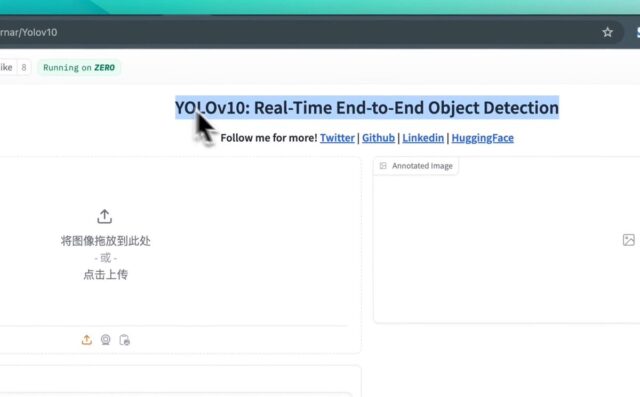
由清华大学多媒体智能组(THU-MIG)开发。 从输入图像到输出检测结果的整个过程全部由模型直接完成,消除了中间的人工干预或额外处理步骤。 YOLOv10 能够在极短的时间内处理输入的图像或视频帧,通…
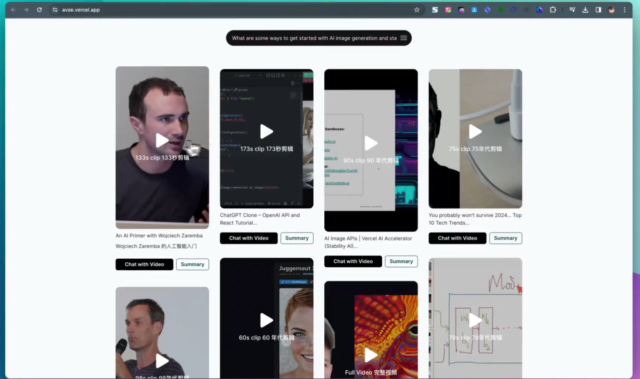
比如,你想知道“如何做蛋糕”,只需在这个网站上输入这个问题,它就会找到相关的视频来帮你解答。 更牛P的是,你还可以跟视频进行对话,就像跟一个人聊天一样,还能帮你总结视频内容。 最牛P的是他把这个项目开…