

百川新模型冲顶中文测试基准!首款AI助手“百小应”同时发布,“最懂搜索”
王小川在搜索时期种下的种子,在大模型时代又开花了。 他创业的百川智能,刚刚发布了自家首款AI应用,to C的“百小应”。 乍一看,这就是个当下大热门的AI助手,但官方强调,这个AI助手啊,它懂搜索,还…
王小川在搜索时期种下的种子,在大模型时代又开花了。 他创业的百川智能,刚刚发布了自家首款AI应用,to C的“百小应”。 乍一看,这就是个当下大热门的AI助手,但官方强调,这个AI助手啊,它懂搜索,还…
用于训练、微调和推理生成模型,涵盖诸如图像生成、转换、编辑等下游任务。 专门用于支持和简化图像生成、合成和编辑任务的开发,包括从文本到图像的生成和高级图像编辑技术。 1、任务支持: 文本到图像生成:支…

该助手能通过语音为玩家提供实时的游戏评论和建议,包括购买建议、对线策略等。 玩家可以在比赛中提出任何关于游戏的问题,并立即获得解答。 每场比赛结束后,玩家可以在赛后大厅页面查看比赛总结,包括各个玩家的…

一、关于教程 之前做过不少pfp头像的项目,这次运用自己手绘草图+AI,使用SD里controlnet和dynamic prompt精准控制不同款式的头像效果,结合视频的方法,大家可以尝试无限组合可能…

视频转动漫所用到的模型和工具下载地址: 链接:https://pan.baidu.com/s/11qa4JWEdrQU5-ennozYGNQ?pwd=3wgl 提取码:3wgl

SSR-Encoder能够提取图像中的多种特征,包括人物、视觉元素、风格、情感和细节等 然后它会利用提取的这些特征再结合文字提示,重新生成新的图像。 比如你看到一张照片,觉得它某一部分很好,就可以指定…
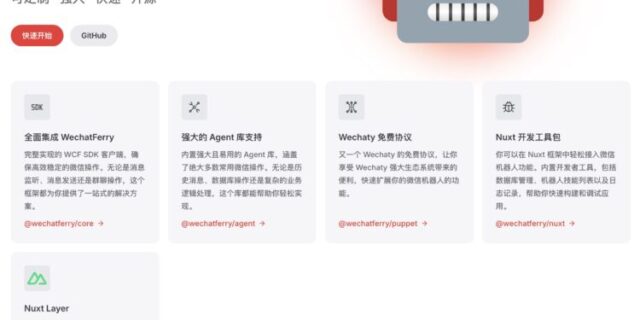
WechatFerry 是一个微信机器人框架,提供了一套强大、快速且可定制的解决方案,适用于开发和集成微信机器人。为开发微信机器人的用户提供了 SDK 封装和多种插件,能够轻松调用微信的相关功能,适用…
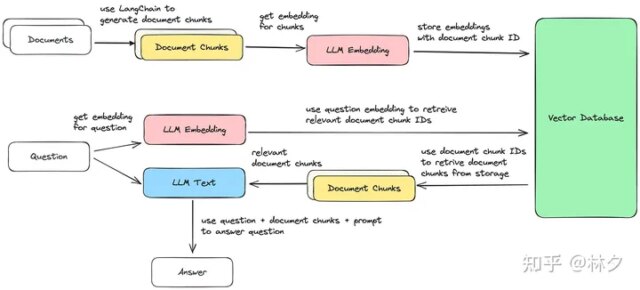
我们都知道Chatgpt有一个严重的问题,就是幻觉,一部分原因是因为ChatGPT缺少该领域的专业知识。借助大型语言模型 (LLM),我们可以集成特定领域的数据来回答用户请求,一定程度缓解这个问题。这…
免费工具 音视频转译 通义听悟 | https://tingwu.aliyun.com/u/758gmq6m6eg9zwoe 音色迁移 speechify | https://speechify.co…
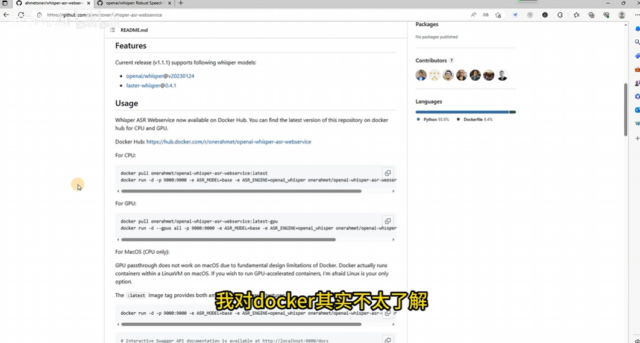
本次视频主要介绍一个Whisper的webservice开源项目,通过docker一键拉取镜像,实现快速部署web api应用,能够很方便的集成到我们的AI二次元小姐姐项目中使用。 视频中所涉及的相关…
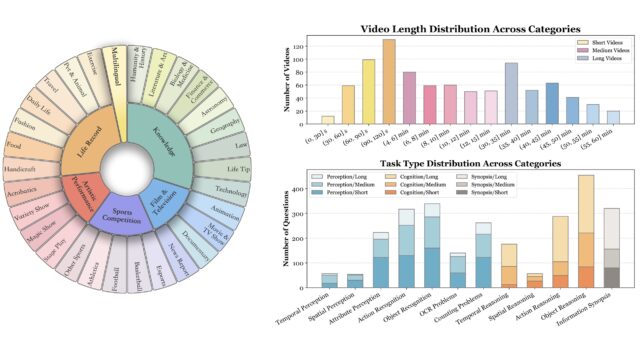
该基准由来自多个大学和研究机构的研究人员共同开发,旨在通过多样化和高质量的数据集,全面考察MLLMs在处理视频数据时的能力。 视频数据集涵盖6个主要视觉领域,包括知识、电影与电视、体育竞技、艺术表演、…
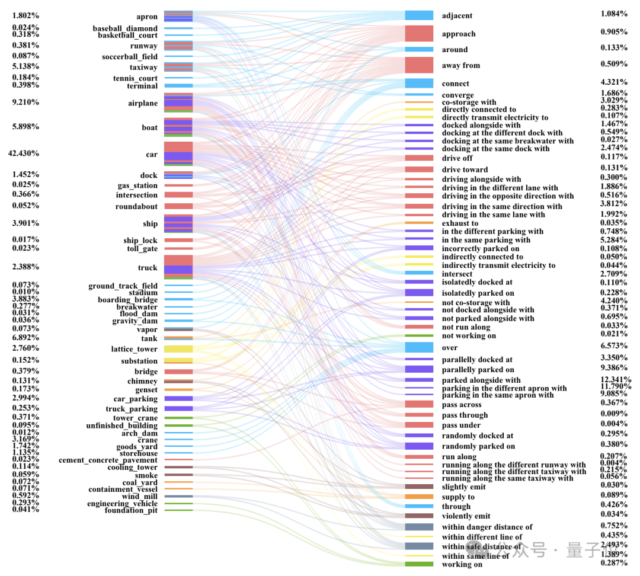
AI卫星影像知识生成模型数据集稀缺的问题,又有新解了。 来自武汉大学、上海AI实验室、西工大等9家机构共同推出了该领域的大型数据集,涵盖了21万个地理目标和40万个目标-关系三元组。 而且像机场、港口…

据国外媒体报道称,ChatGPT背后的OpenAI计划自研AI芯片,以解决其所依赖的AI芯片短缺以及成本高昂问题,甚至已经开始评估潜在的收购目标。 据知情人士表示,OpenAI至少从去年就已经开始讨论…
AI时代让太多的人产生焦虑,文生动画工具,是否让动画师和摄影师进入失业倒计时? 给大家进行了10大文生动画工具的详细测评,看看最先进的AI动画技术能到哪一步了

据新浪科技爆料,百度或将于 2025 年百度世界大会期间发布新一代文心大模型5.0。 目前,文心大模型最新版本为 4.0 版本。

DreaMoving能仅靠脸部照片和文字提示就能生成在任何场景下跳舞的视频… 测了下跳舞动作还可以,但是和背景融合度不行,人物舞蹈和背景完全是隔离的,不能完全融合! 体验地址:https:…

从草图到成品,思路讲解,过程展示
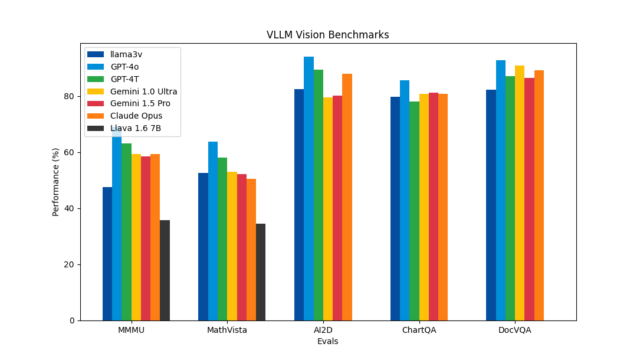
在几乎所有指标上,Llama 3-V 的性能与GPT-4V、Gemini Ultra和Claude Opus等规模大100倍的闭源模型相当。 唯一的例外是MMM U(多模态记忆任务),Llama 3-…

1、GFPGAN-腾讯开源的照片修复工具 https://github.com/TencentARC/GFPGAN 2、视频,图像和GIF无损放大/放大(超分辨率)和视频帧插值 https://git…

Anthropic发布了一篇文章介绍了Claude3的性格训练内容及方法,Anthropic设计的Claude 不仅避免伤害,还具备积极的人类特质如好奇心和开放思维。这种方法帮助Claude 更周到地…