麻省理工大学研究团队开发出一种新技术:Ddog
通过脑电波控制波士顿动力的机器狗。 该技术仅靠一种特殊的眼镜就能读取人的脑电波和眼动,然后把这些信号传递给机器人执行动作。 Ddog系统只需要两 iPhone和一副蓝牙眼镜就可以运行。而且还可以完全离…
通过脑电波控制波士顿动力的机器狗。 该技术仅靠一种特殊的眼镜就能读取人的脑电波和眼动,然后把这些信号传递给机器人执行动作。 Ddog系统只需要两 iPhone和一副蓝牙眼镜就可以运行。而且还可以完全离…

丨划重点 ① 没有必要害怕超级智能的人工智能,因为与未来的模型相比,每个新模型都被认为能力不足,进而推动了持续的改进。 ② 仅仅专注于解决当前的人工智能限制可能是徒劳的,因为像GPT-5和GPT-6这…

OpenAI的首席执行官Sam Altman最近向一些股东表示,公司正在考虑改变其治理结构。 OpenAI正在考虑将治理结构转变为营利性公益公司,脱离非盈利董事会的控制。 这一变动可能为OpenAI的…
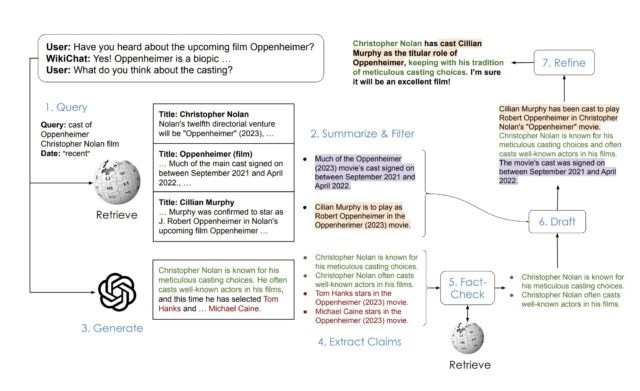
WikiChat基于英文维基百科信息。当它需要回答问题时,会先在维基百科上找到相关的、准确的信息,然后再给出回答,保证给出的回答既有用又可靠。 在混合人类和LLM的评估中,WikiChat达到了97….
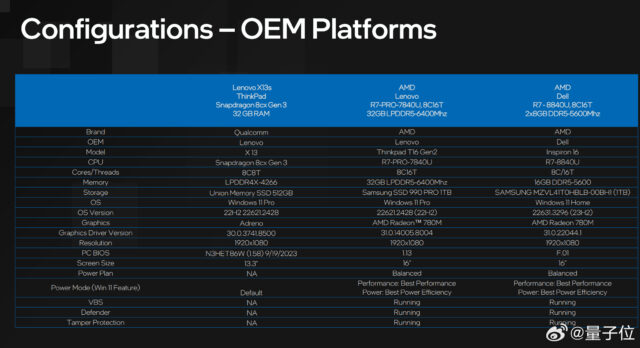
英特尔官方最新宣布—— 自今年第3季度起到假日季,其即将到来的客户端处理器 Lunar Lake 将继续扩大全球AI PC规模,并在未来可用时免费升级 Windows 11 AI PC体验。 Luna…

能聊天、能生图、能出视频 还支持包括搜索和替换、背景移除、创意放大、结构控制、外绘和草图等功能。 倒闭边缘的盈利尝试…
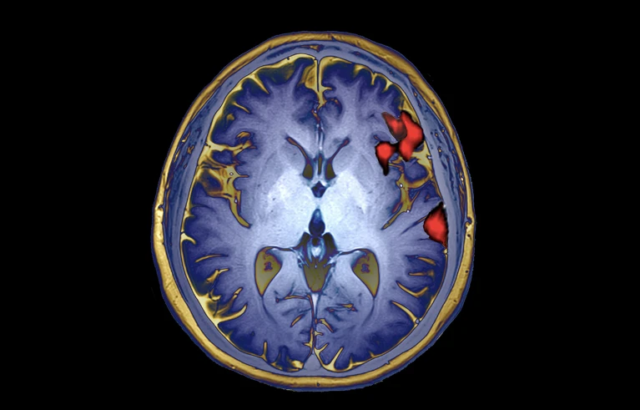
加州大学旧金山分校的研究人员刚刚开发出一种大脑植入物,研究人员成功地帮助一名失去说话能力的双语患者通过脑植入设备实现了双语交流。 这一系统由人工智能(AI)与脑植入设备结合而成,能够实时解码患者试图表…

生命科学领域的基础大模型来了! 来自清华、百图生科的团队提出的单细胞基础大模型scFoundation,登上Nature Methods。 该模型基于5000万人类单细胞测序的数据进行训练,拥有1亿参…

“欧洲AI春晚”主论坛现场,李彦宏最新亮相,作为大会唯一受邀中国企业家,再一次为中国AI“代言”。 这场正在法国巴黎举办的大会全称“欧洲科技创新展览会”(Viva Technology),是欧洲规模最…
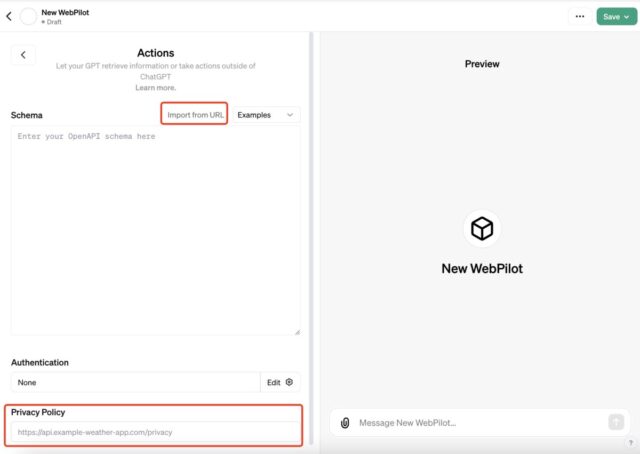
可以把 GPTs 的action的网络功能换车 WebPilot WebPilot的网络功能我用下来更快、效果更好一些 设置步骤: 1、在GPTs配置标签中,向下滚动并取消勾选“Web Browsin…
ChatGPT PLUS的所有付费功能都在这里,来看看你用不用得上吧!
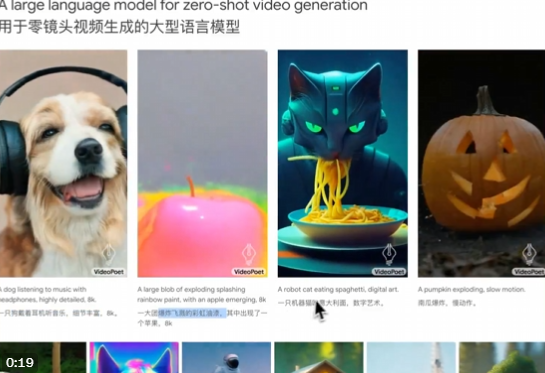
它可以根据文字描述来生成视频。但它不是基于扩散模型,而本身就是个LLM,可以理解和处理多模态信息,并将它们融合到视频生成过程中。 不仅能生成视频,还能给视频加上风格化的效果,还可修复和扩展视频,甚至从…
2003年夏天的一个周日,AI教父Hinton在多伦多大学的办公室里敲代码,突然响起略显莽撞的敲门声。 门外站着一位年轻的学生,说自己整个夏天都在打工炸薯条,但更希望能加入Hinton的实验室工作。 …
提升打字体验 Proofread 是由Google提出一种基于大语言模型的一键式纠错功能,以提升用户的打字体验。 通过一次点击,可以自动修正他们输入的文本中的所有错误,你在打字过程中甚至无需在意输入的…

自去年11月底ChatGPT横空出世,已经过去了近一年的时间。 在本期视频中,将回顾GPT在过去一年的发展历程, 并结合OpenAI的研发方向和Sam Altman最新访谈内容, 展望GPT5的实际形…

在AI-2.0时代,OCR模型的研究难道到头了吗!? (OCR:一种将图像中的文字转换为可编辑和可搜索文本的技术) Vary作者团队开源了第一个迈向OCR-2.0的通用端到端模型GOT。 用实验结果向…
国产o1新选手登场! 它能快速解决更复杂的数学解题、代码编程、数字游戏等任务。 这就是上海AI实验室版o1——强推理模型书生InternThinker,刚刚正式开放试用! 新模型不仅在长思维能力方面有…
后续会更新更多AI绘画、设计相关的教程,欢迎关注!
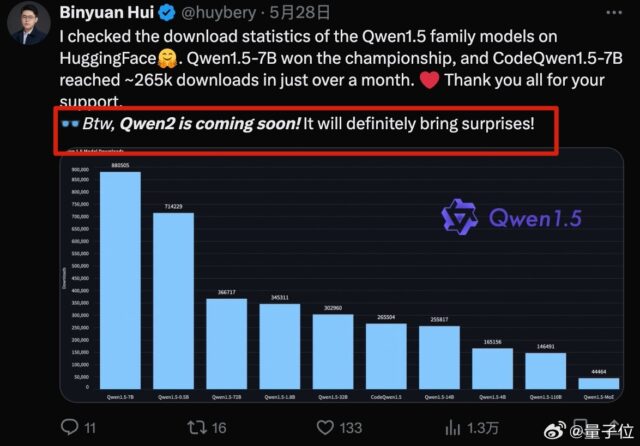
Qwen1.5 来了,Qwen2还会远吗 还在上个月,阿里推出了国内开源模型中参数规模最大的 Qwen1.5-110B 模型。 根据官方公布的评测结果,Qwen1.5-110B略超过Llama-3-7…