

OpenVoice:多功能即时语音克隆
由MyShell TTS开发。它能够仅使用一小段参考发言者的音频片段来复制其声音,然后能生成多种语言的语音。 OpenVoice能对声音风格的精细控制,包括情感、口音、节奏、停顿和语调,同时能够复制参…
由MyShell TTS开发。它能够仅使用一小段参考发言者的音频片段来复制其声音,然后能生成多种语言的语音。 OpenVoice能对声音风格的精细控制,包括情感、口音、节奏、停顿和语调,同时能够复制参…
据 Forbes 爆料,OpenAI 正在重组于2020年解散的机器人团队。 该公司正在招聘研究工程师,以组建一个新的团队,目前已经存在约两个月。 OpenAI 尚未公开详细介绍其机器人计划,但在最近…
已经有超过300万个GPTs被创建 同时OpenAI将启动一个GPTs构建者收益计划,美国构建者将根据用户与他们的GPTs互动情况获得报酬。 ChatGPT Team订阅计划每月每用户25美元(年度计…
OpenAI的新王炸GPT-4o还没全面铺开,就摊上事了! 抓马的是,此次推出的“视频通话”功能一度被称为电影《Her》现实版,而怒斥OpenAI的刚好是给电影中AI配音的斯嘉丽·约翰逊(寡姐)。 寡…
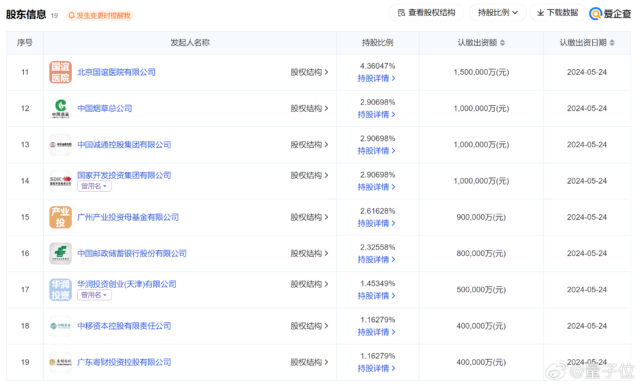
国家集成电路产业投资基金三期(大基金三期)正式成立,注册资本3440亿元。 此次投资比一期(987.2亿元)、二期(2041.5亿元)总和更多。 这是中国芯片领域史上最大规模基金项目,也是芯片领域最新…

10月8日消息:微软日前宣布将对 OneDrive 进行更新,旨在使人们更容易访问、查看、分享和管理他们的文件。 在本周的在线活动中,被称为「微软 OneDrive:文件管理的未来已经来临」,微软公司…

OpenAI宣布ChatGPT的一项重要更新:增加了记忆功能和新的用户控制选项。 GPT现在可以在与用户的交互中跨聊天记住你们互动的所有信息,并在后续对话中利用这些信息来提供更相关和个性化的回答。 之…
ChatDev是OpenBMB的发起者——面壁智能(ModelBest)联合清华大学NLP实验室共同开发的大模型全流程自动化软件开发框架,火遍全球,开源6周获星标13k,吸引国内外众多软件开发和创业者…
近日高通已经正式宣布,将于10月25日-10月26日举行2023骁龙峰会,届时一大波新品将正式登场。 其中最受关注的莫过于新一代旗舰移动平台骁龙8 Gen3。 这将是今后一年中,旗舰手机的标配移动平台…

清华智谱AI第三代大语言模型 ChatGLM3发布,性能如何?

它可以从多人对话中语音中生成与对话相对应的逼真面部表情、完整身体和手势动作。 这些生成的虚拟人物不仅在视觉上很逼真,而且能够准确地反映出对话中的手势和表情细节,如指点、手腕抖动、耸肩、微笑、嘲笑等。 …

根据新版隐私权政策,用户将同意将自己发布的任何内容用于 AI at Meta 模型训练。 如果用户选择不同意该隐私权政策则应该主动停止使用 Facebook 和Instagram等产品,否则均为接受新…

可在消费级笔记本电脑上运行 该模型包含 20 亿个参数。在图像质量上有显著提升,能够生成更高质量、更细腻的图像。能够更准确地将文本描述转换为图像。 Stable Diffusion 3 Medium …
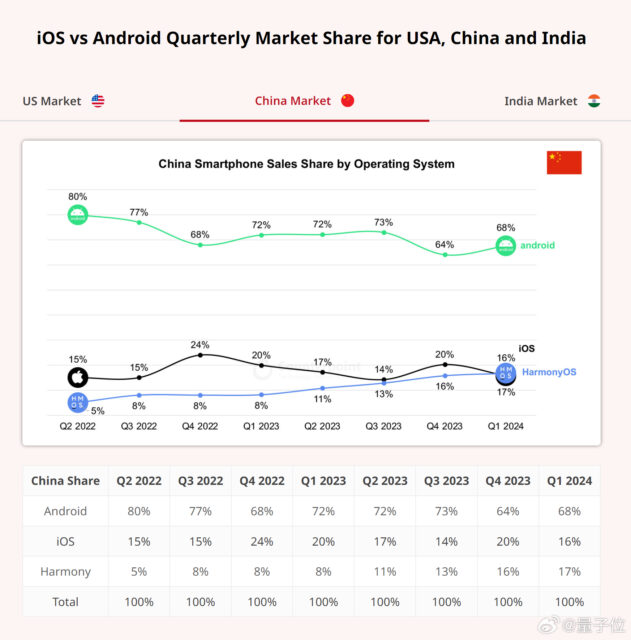
调研机构 Counterpoint 发布报告称—— 在中国市场,华为鸿蒙OS 首次超越了 iOS,市场份额达到了 17%,成为国内第二大手机操作系统。 数据显示,Android 和 iOS 在全球市场…

只用提示词,多模态大模型就能更懂场景中的人物关系了。 北京大学最新提出多模态提示学习(Conditional Multi-Modal Prompt, CMMP)方法,利用提示词工程技术教会多模态大模型…

通过这项技术,你可以让一个虚拟的3D人物模型模仿真实人的表情和头部动作。 而且这个过程是实时的,通过摄像头输入,当真人改变表情或头部姿势时,3D模型也会立即做出相同的反应。 通俗来说就是:3D变脸术 …

清华博士秦禹嘉最近发表一篇博文称:是时候把数据scale down了! LLaMA3告诉大家一个悲观的现实:模型架构不用动,把数据量从2T加到15T就可以暴力出奇迹。 这一方面告诉大家基座模型长期来看…

刚刚,谢赛宁&Lecun团队官宣新成果—— 正式推出以视觉为中心的多模态大模型Cambrian-1! 模型名为“寒武纪”,谢赛宁本人激动表示: 就像在寒武纪大爆发中生物发展出更好的视力一样,我…
保持良好平台绿色生态,你我有责~
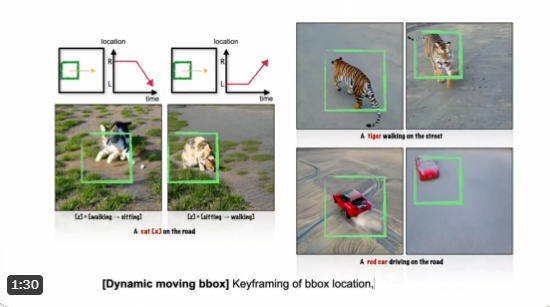
TrailBlazer是英伟达的一个预训练好的模型,只需输入文本即可生成视频。 同时他们提出一个边界框的概念,来控制视频对象的运动方向、速度和行为。 例如,你可以通过改变边界框的大小、方向,让视频中的…