
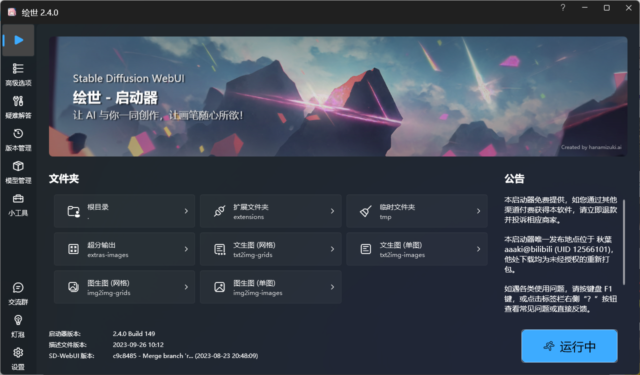
Stable Diffusion绘世整合版 安装使用教程
一、概述 本文使用秋叶大佬发布的【绘世整合包】作为软件,它是目前市面上最易于使用的整合包之一,无需对网络和Python有太多的前置知识,已经为AI绘画的普及做出了巨大贡献。绘世启动器整合包于2023年…
一、概述 本文使用秋叶大佬发布的【绘世整合包】作为软件,它是目前市面上最易于使用的整合包之一,无需对网络和Python有太多的前置知识,已经为AI绘画的普及做出了巨大贡献。绘世启动器整合包于2023年…

– Rodin Gen-1拥有1.5B参数,是目前最大的3D原生生成大模型。它的功能类似于SD(Stable Diffusion)。 – 3D-to-3D:除了传统的3D建模,…

一、关于教程 我最近的工作中经常会用SD批量生图并且放大,所以今天打算分享一下Tiled Diffusion和Tiled VAE插件结合ControlNet进行批量放大的流程。 需要提醒大家的是,这个…
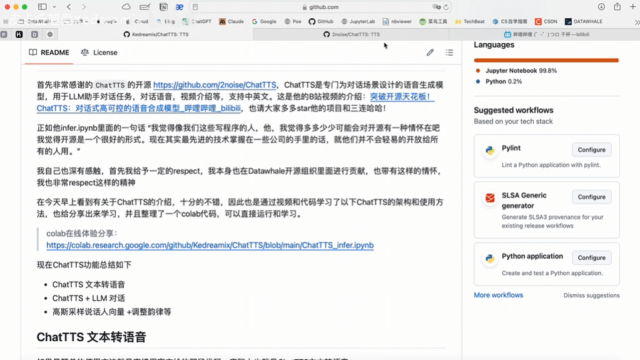
该视频介绍了ChatTTS的核心功能,包括文本转语音、与LLM对话集成及韵律调整等。如何使用ChatTTS生成自然流畅的对话语音,并分享了调整韵律和生成多样化说话人向量的方法。 colab在线体验:h…

Topaz全家桶(Win系统和Mac系统),特别注意:不要直接点击下载全部(999+警告),建议是进入链接对应文件夹里边保存所需安装包进行下载。 阿里云盘:https://www.aliyundriv…
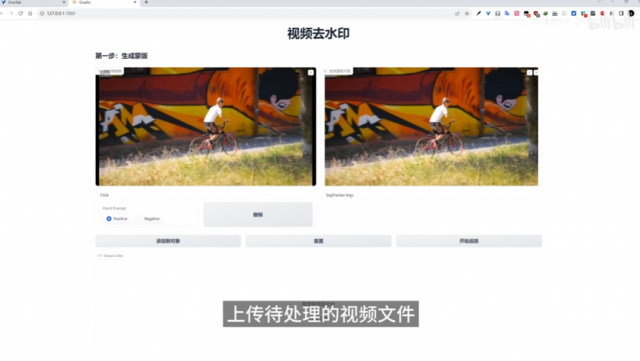
propainter 原项目地址 https://github.com/sczhou/ProPainter propainter 整合包第二版下载地址 链接:https://pan.baidu.com…
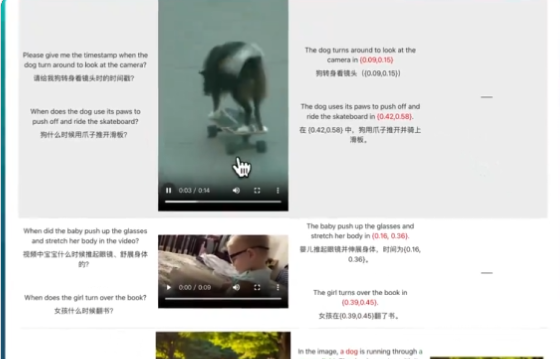
LEGO能够处理和理解多种类型的输入,支持图像、音频和视频输入,并对这些信息进行分析和理解。 模型还具备精准定位的能力。例如在图像中标识出物体的具体位置,在视频中指出特定事件发生的时间点,在音频中识别…
该模型由腾讯与新加坡国立大学开发,M2UGen能够理解各种音乐,包括风格、演奏乐器、表达的情绪情感等,并进行音乐问答。 而且还能根据文本、图像、视频和音频生成各种音乐,同时对生成的音乐也能理解并根据文…
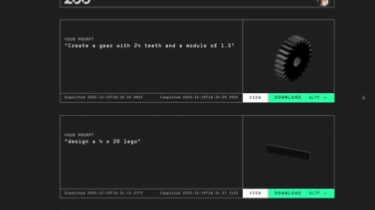
只需要输入自然语言描述,它就能根据这些描述创建相应的 B-Rep CAD 文件和网格模型。 生成的模型可以导入到用户选择的任何 CAD 程序中。 Text-to-CAD 背后的基础设施利用了 Zoo …
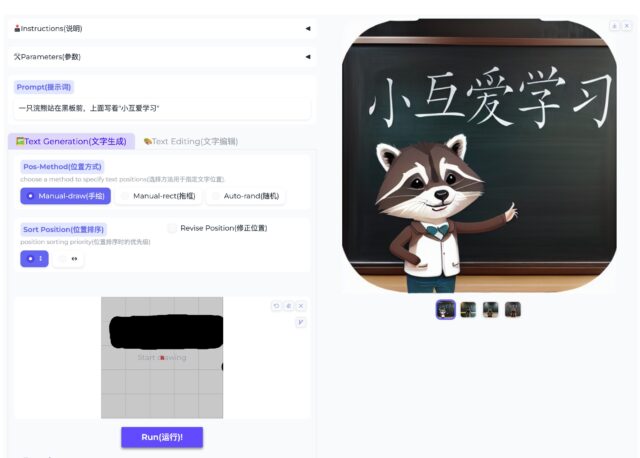
该项目由阿里巴巴开发,AnyText支持在图像中生成和编辑多种语言的文本,使其与背景无缝融合。 该模型还解决了合成文本中模糊、不可读或错误字符的问题。 AnyText可以与现有的扩散模型集成,用于准确…
Fooocus,10月22日2.1.724版本。 本版本包含图生图的控制和融合,线稿上色,无损放大,内部重绘,外部扩展等等多项功能,已经比较完善了。 官方重大更新对动漫和现实的高度支持,直接用启动器即…

腾讯 AI 实验室开发出一种名为“TRANSAGENTS”的新型多智能体框架,用于超长文学内容翻译。 它使用虚拟角色模拟真实的翻译公司,包含多个角色,比如高级编辑、初级编辑、翻译员等。 每个角色负责不…
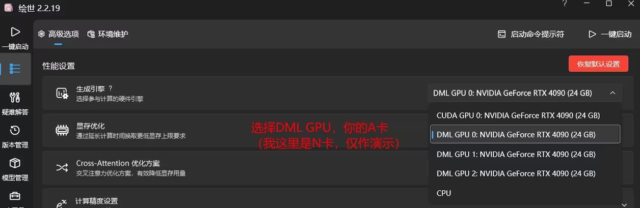
基于 lshqqytiger 分支制作,功能与 v4.4 版本整合包相同 仅经过朋友一台电脑测试,不保证完全可用,若发现无法使用请及时评论区反馈 使用方法和普通整合包完全一致,首次使用打开启启动器后,…
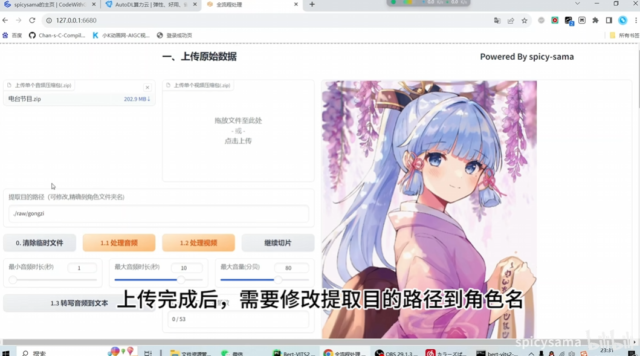
临时Q群:875965154 ※※更新已放出 https://github.com/AnyaCoder/Bert-VITS2/tree/v1.1.1-new 1014-加入多人多语言合成 1013-加…

本期视频所涉及的程序: CUDA下载安装 :https://developer.nvidia.com/cuda-downloads ChatGLM3 一键部署包: https://pan.baidu….
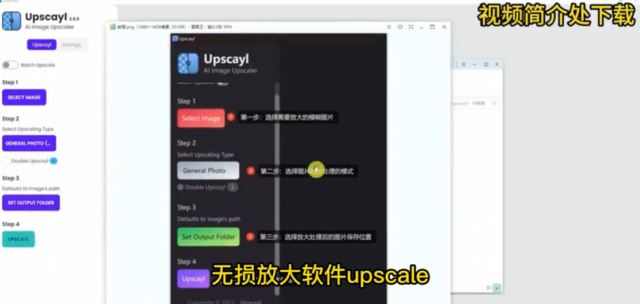
【下载地址】:https://pan.quark.cn/s/9f0fec66c8b7 国外爆火出圈!极品AI图片无损放大器,模糊图片秒变清晰,一键修图

【视频附件】 以太转绘工具包(@胡里胡涂大哥 ): https://github.com/huchang47/AetherConverTools isnetpro(单帧/文生图/图生图/动态倍率脚本@…

T2I-Adapter 是一种高效的即插即用模型,其能对冻结的预训练大型文生图模型提供额外引导。T2I-Adapter 将 T2I 模型中的内部知识与外部控制信号结合起来。我们可以根据不同的情况训练各…
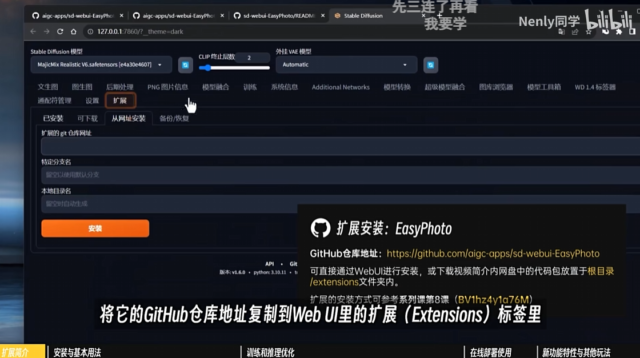
EasyPhoto扩展地址:https://github.com/aigc-apps/sd-webui-EasyPhoto 提示词模版和插件模型下载:https://nenly.notion.site…
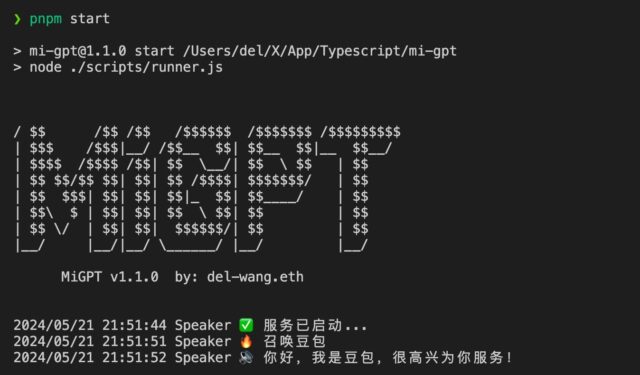
让小爱音箱和其他米家智能设备能更好地理解和响应用户指令,并且还可以直接和智能家居联动! 主要功能: 1. 小爱音箱可以使用 ChatGPT 等大模型来回答问题。 2.角色扮演:小爱音箱可快速切换角色,…
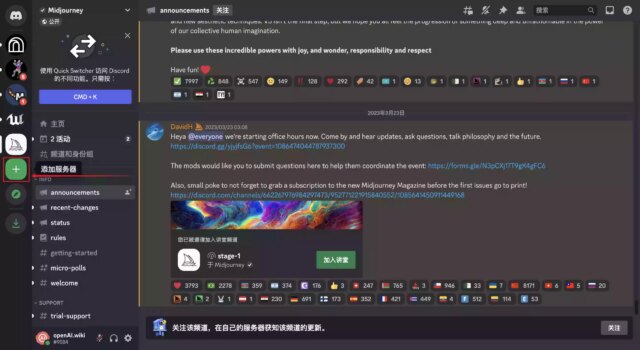
Midjourney进阶教程|私人服务器的使用与创建 自建服务器 首先我们点击Discord中最左侧的绿色添加服务器按钮,如下图所示: 在弹出的创建服务器界面内,点击亲自创建按钮。 左图中选择仅供我和…
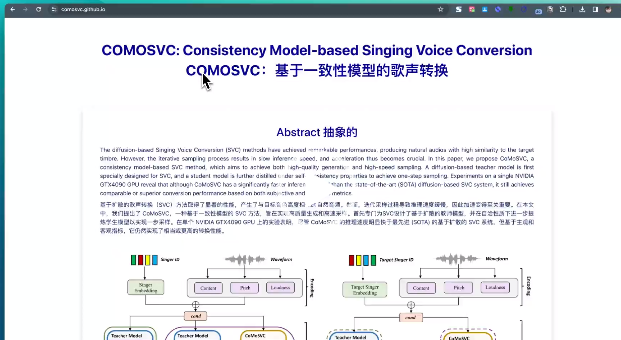
它可以将一个人的歌声转换成另一个人的歌声。同时能够保持了声音的自然度和真实感。 最牛P的是CoMoSVC实现了一步采样。意思是它可以在单次操作中即可完成声音的转换,大大加快了处理速度。 该项目由香港大…
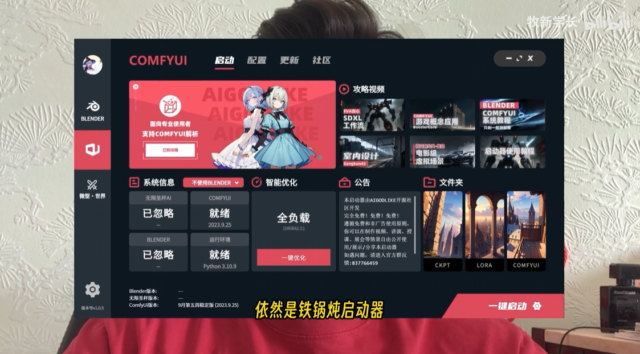
专为COMFYUI使用者设计,无论是在原生WEB还是Blender中使用,均可实现稳定且高效的对COMFYUI维护升级、一键优化和参数配置等功能。遵循免费和非广告使用原则,你可以在制作视频、讲演、授课…

这个语音专文本TTS模型 应该是目前对中文支持最好的了 该模型经过超过10万小时的训练,公开版本在 HuggingFace 上提供了一个4万小时预训练的模型。 专为对话任务优化,能够支持多种说话人语音…
工作流分享:https://pan.baidu.com/s/1P-OBYCs54acZ_AiSzLWJ6g?pwd=mxxz

目前的图像生成模型,再生成图像方面已经非常出色,但在生成人类手部的图像时却常常出现问题,比如手指数量不对或者手形怪异。 HandRefiner提出一种方法,在不改变图片其他部分的情况下,修正那些形状不…
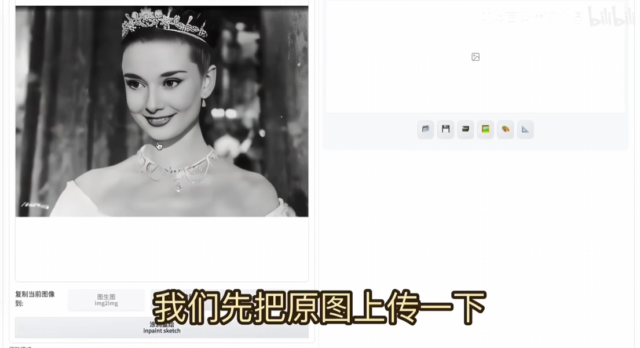
今天我们来介绍一款一键上色神器 Recolor,也是最近 ControlNet 上新的一款新模型。Recolor,顾名思义,是给图片重新上色。我们不仅可以用它来给漫画上色,还能给图片随机改颜色。 小捏…

Genie是一个文本到3D模型的转换工具,能够在不到10秒内根据文本描述创建任何想象中的3D对象。 生成的3D模型不仅包含形状,还包含了表面材料的细节,比如颜色、纹理或反光性,这使得模型更加逼真和详细…